type
status
date
slug
summary
tags
category
icon
password
AI summary
背景
又是一次喜闻乐见的RocketMQ的消费问题,并且也还是熟悉的配方:执行导出任务的时候没有限制行数,导出了全表数据,导致消费耗时长达半个小时以上。并且由于最后生成的excel导出文件太大,上传oss也报错了,消息无法成功消费,在RocketMQ的失败重试的机制下,不停的在重试。
更棘手的是,整个过程中,该应用还有不止一次的发布(正常的应用迭代发布)。发布的启停会触发
rebalance,这些rebalance会让整个消费日志更加的扑朔迷离。我花了将近3天的时间来厘清这些消费日志产生的原因,这其中包括:- 对于RocketMQ相关知识点的复习
- 结合日志和源代码来猜测和验证原因
下面我会把这个过程记录下来,如果你也刚好碰到类似的问题,希望对你能有一定的帮助。
知识回顾
首先,这里先回顾一下关于RocketMQ消息消费的相关知识:
RocketMQ 生产消费模型
RocketMQ通过
topic来区分不同的主题,每个topic下面又会分成N个MessageQueue,这些MessageQueue就是具体的消息队列。生产者会在发送消息的时候需要指定对应的topic,并且通过一定的路由算法,发到具体的MessageQueue中。这些
MessageQueue会由订阅的ConsumerGroup来消费。设计上,一个MessageQueue只能被ConsumerGroup下的一个消费实例消费。而具体的消费实例和MessageQueue的对应关系则是通过一个rebalance的过程来分配,并且这个过程Broker只负责通知(一般是由于ConsumerGroup里的consumer的上下线触发),最终是由consumer接到通知之后自己来分配的,每个consumer都用同一套逻辑给自己分配,以此来保证一致性。可以通过下面这张图加强理解
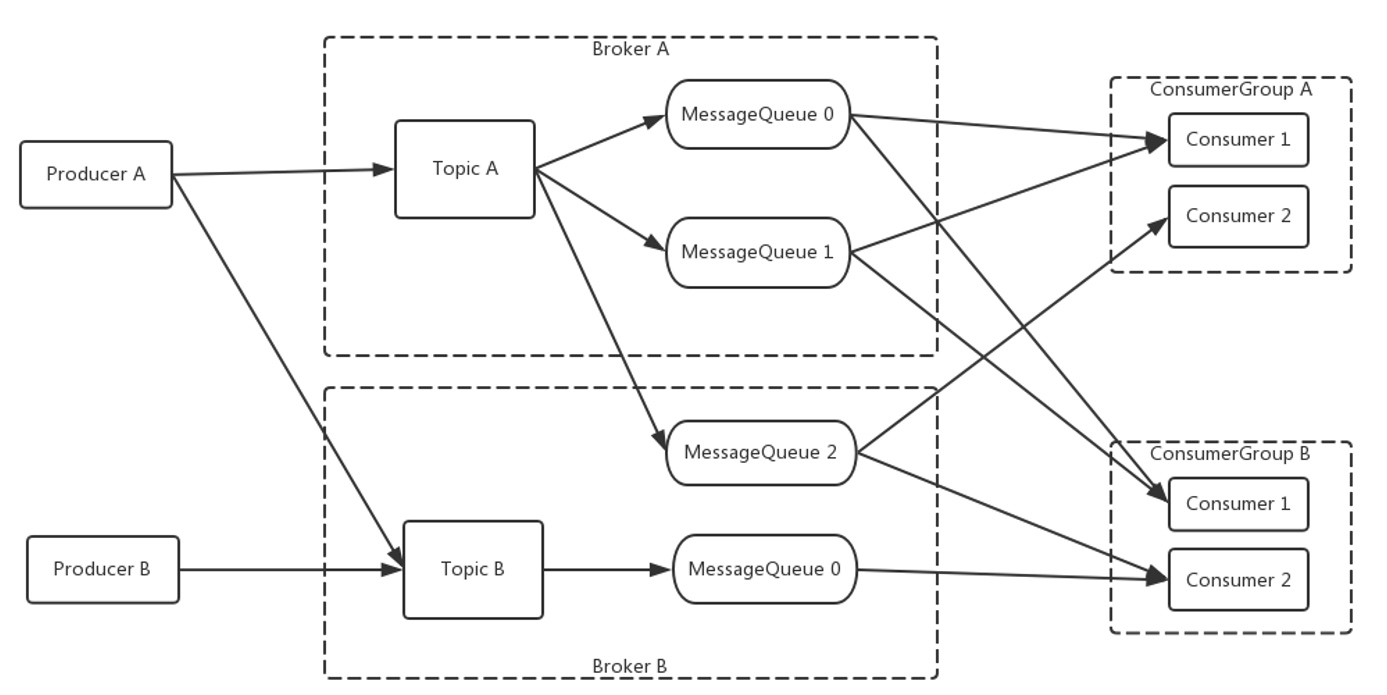
RocketMQ 消息消费重试实现原理
针对消费失败的场景,RocketMQ有自己的重试策略。
第几次重试 | 与上次重试的间隔时间 | 第几次重试 | 与上次重试的间隔时间 |
1 | 10秒 | 9 | 7分钟 |
2 | 30秒 | 10 | 8分钟 |
3 | 1分钟 | 11 | 9分钟 |
4 | 2分钟 | 12 | 10分钟 |
5 | 3分钟 | 13 | 20分钟 |
6 | 4分钟 | 14 | 30分钟 |
7 | 5分钟 | 15 | 1小时 |
8 | 6分钟 | 16 | 2小时 |
但是这个重试具体是怎么实现的呢?其实是需要依赖于consumer自己在发现消费失败之后重新投递“新的重试消息”。所以这个间隔是不包含消费时长的,当然,这也符合常规理解。
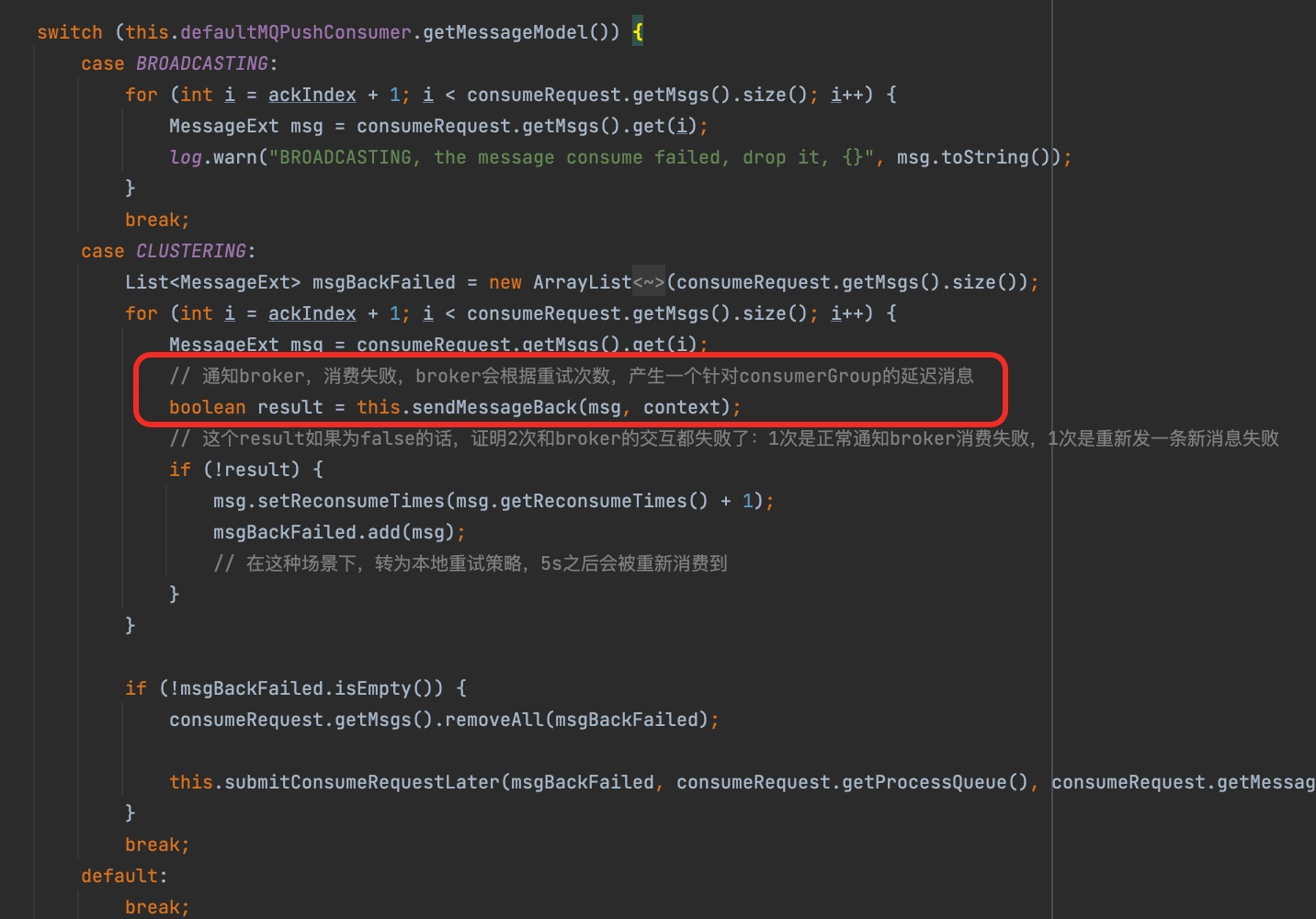
RocketMQ ConsumerGroup消费进度更新机制
这里只聊集群消费的场景,而对于时序性要求没有那么严格的场景,我们一般都采用无序并发消费(
ConsumeMessageConcurrentlyService)的方式。这种方式是由消费实例从
Broker拉取对应的MessageQueue 下的一批消息(默认应该是32条),然后用一个线程池并行去消费,不保证顺序性。这样就会产生一个问题,如果offset大的消息被先消费成功了,它不能直接更新消费进度,不然万一宕机了,就可能出现offset较小的消息实际并没有被成功消费但是看起来被成功消费了。为了保证At Least Once的语义,RocketMQ为每个Consumer设计了一个ProcessQueue来维护正在处理的消息列表,然后在每个消息消费成功/失败的时候会去检查这个ProcessQueue,如果还有消息正在消费,那么会直接用这个正在消费的消息的offset来作为整个ConsumerGroup的消费进度。并且也会记录一个队列最大的offset,当整个ProcessQueue被消费完时,会把offset更新成这个最大的。另外,
ConsumerGroup 的消费进度并不会每次都更新到Broker,消息消费完成之后的进度推进都是在内存里的。内存里的进度默认每隔5秒定时往Broker同步。这两个机制毫无疑问地增加了消息被重复消费的可能性。
分析
下面就是具体的分析过程,为了如实还原,我分析了每一次的消费行为。所以整个过程会显得非常冗长和枯燥,但是我又不太想删掉(原谅我舍不得丢破烂),权衡之下,我决定用另外一篇文章记录完整的日志分析过程。这篇文章只对最令人疑惑的几个点展开分析。
为什么reconsumeTimes=0的消息消费了3次?
这个问题比较容易回答。因为在应用发布的时候,一停一启,都会造成
ConsumerGroup里的消费实例变更。消费实例变更会上报给Broker,Broker又会把这些信息广播给ConsumerGroup下的所有实例,触发rebalance。这样就会影响到消费实例和MessageQueue之间的消费关系,而同一条reconsumeTimes=0的消息被消费了3次的原因就是:- 第一次,
10.11.27.153,正常消费
- 第二次,原消费实例
10.11.27.153下线,触发一次rebalance,转移到10.11.27.156消费
- 第三次,原消费实例
10.11.27.153上线,触发一次rebalance,转移到10.11.27.154消费
但是为什么
10.11.27.153重新上线之后,并不是它接手原队列,而转移到了10.11.27.154呢?这引出了第二个问题,rebalance是否合理?我们来需要结合当时的日志来还原rebalance的过程。验证rebalance的过程
我们先来看看当时的消费实例上下线情况,这是从其中一台broker日志里的消费实例上下线日志提取的:
我们把它和当时的消费实例上下线情况用表格的方式呈现:
机器ip | 实例下线时间 | 实例上线时间 | 初始分配 | 15:09:14分配 | 15:09:28分配 |
10.11.27.144 | 15:11:10 | ㅤ | broker-a[0] | broker-a[0] | broker-a[0] |
10.11.27.147 | 15:11:09 | ㅤ | broker-a[1] | broker-a[1] | broker-a[1] |
10.11.27.148 | 15:11:10 | ㅤ | broker-a[2] | broker-a[2] | broker-a[2] |
10.11.27.149 | 15:11:10 | ㅤ | broker-a[3] | broker-a[3] | broker-a[3] |
10.11.27.150 | 15:16:27 | ㅤ | broker-a[4] | broker-a[4] | broker-a[4] |
10.11.27.151 | 15:09:14 | 15:10:32 | broker-a[5] | ㅤ | ㅤ |
10.11.27.152 | 15:11:09 | ㅤ | broker-a[6] | broker-a[5] | broker-a[5] |
10.11.27.153 | 15:09:13 | 15:10:27 | broker-a[7] | ㅤ | broker-a[6] |
10.11.27.154 | 14:37:07 | ㅤ | broker-b[0] | broker-a[6] | broker-a[7] |
10.11.27.155 | 15:09:13 | 15:10:28 | broker-b[1] | ㅤ | broker-b[0] |
10.11.27.156 | 15:18:16 | ㅤ | broker-b[2] | broker-a[7] | broker-b[1] |
… | … | ㅤ | ㅤ | ㅤ | ㅤ |
首先,该topic的常规队列总共是有
16个MessageQueue,broker-a[0-7]和broker-b[0-7],消费组下的消费实例总共有24台(这里未画全)。而目标消息存在于broker-a[queueId=7]。这个队列初始状态下由10.11.27.153消费。默认的分配策略是
AllocateMessageQueueAveragely是把MessageQueue和实例信息(ip+instanceName)从大到小排序,然后按顺序平均分配。除不尽的话,靠前面的实例每个会多分走一个。
所以初始的分配,以及后面2次的
rebalance,根据当时的实例在线情况,验证都是符合预期。当然,这里都还是一个中间过程,因为第二次
rebalance的时候,10.11.27.151这台机器还没有上线。等它上线之后(也就是15:10:32),还会触发rebalance,只要机器的实例信息都没变的话,最终的消费关系还是会回到初始时的分配状态。已经被提交的消息还能被消费到?
如果消息没被提交,那么在
MessageQueue被其他消费实例接手时,肯定能从没被提交的offset继续消费。但是为什么已经提交的消息还能被消费到?从上图我们可以看到第13步的消费已经在16:34:28消费失败,并且提交了重试消息到Broker(这个可以通过第15步消费的时间点看出来,刚好差7分钟,和第13步消费失败的时间点相吻合)。这么看来,肯定是执行到了
sendMessageBack逻辑,但是为什么Broker端的消费进度并没有往前推进呢?sendMessageBack 在上文只是回顾的时候有提及,它是在消息消费失败时,Consumer往Broker投递的下一次重试(reconsumeTimes+1)消息的流程。翻阅源代码,我发现存在几种情况可能导致
offset不会往前推进:- 本地
offset未同步到Broker,因为ConsumerGroup的消费进度是先在内存更新,然后通过一个线程每隔5秒往Broker同步的。不过这里已经将近4分钟了,肯定不是这个问题。
- 如果在消费结束时对应的
MessageQueue已经不再是由我这个消费实例接管的话,那offset也不会往前推进。但是同样的前提也适用于sendMessageBack,这里显然已经执行了sendMessageBack。除非就是临界情况:在sendMessageBack后被其他实例接管。理论上是存在这种可能性的。但是我们这个场景里,重试队列也是在将近4分钟之后才被接管的,也不会是这个问题。
- 同个
MessageQueue,还有正在消费的消息,且消息的offset比本消息的offset要小
看起来只存在第三种场景了,剩下的就是找日志验证了。看了这个任务的重试消息,发现当时该实例上的所有消费应该都结束了。但是,后来发现还存在另外一个同类型的任务也在重试,由于同一个
ConsumerGroup的重试队列只有一个,所以另一个任务产生的重试消息也在其中,当时另一个任务的消息有正在进行中的消费,所以导致消费进度无法往前更新。为什么一条原始消息,会被反复消费40多次?
对于同一条原始消息,默认情况下,算上重试应该最多也只会有
16次,那么多出来的几十次是怎么产生的呢?如果从“实体的”重试消息来看,重试队列里总共有30个消息,这都比预期的要多。这是为什么呢?相信如果你认真看到了这里,应该会有一些思路:
- 消费过程中,
MessageQueue消费权变更,这里存在两种情况 - 消息的消费确实还在进行中,但是由于
rebalance产生消费权变更 - 消息已经消费完成,但同一
MessageQueue里还有offset比当前消息更小的正在消费的消息 - 消费实例本地内存进度未及时同步给
Broker,发生宕机
- 重复消费且消费失败,会重新投递一个重试消息,会进一步增加重复消费的次数
产生rebalance的原因一般来说就是消费实例的上下线,最常见的就是应用发布,一个实例的发布会产生一次下线、一次上线,理论上至少触发两次
rebalance。所以你可以在发布过程当中关注关注Consumer的日志,可能会有一个更深的理解。优化策略
出问题的时候,其实我们是有点束手无策的,没有一个快速止血的办法。只能临时改代码,直接注释掉消费逻辑让消费赶紧结束,再通过增加筛选条件及限制导出行数的手段来解决问题。
但是细想一下,这个问题在重试放大的情况下,有可能直接把应用打死,比如导致应用内存溢出或者是跑满带宽/磁盘等等问题。所以我们需要对这块做一些优化。
分布式锁的续约
假设这里的分布式锁会自动续约,那么是不是能减轻这个问题?应该是可以一定程度上减轻的,至少能保证同一时间只会有一个消费线程在执行对应的逻辑。而我们实际的消费日志里已经出现几个消息并行消费的情况了。
减少消息重试次数
我们没有人为调整消息的重试次数,默认
16次。其实可以在
Consumer的维度配置最大重试次数。这个参数作用在Broker端的sendMessageBack方法里,消费失败之后,由Consumer端带上消费次数以及最大重试次数交由Broker端判断,如果超过最大重试次数则丢入DLQ队列,如果没超过则丢入SCHEDULE_TOPIC_XXXX队列(最后由Broker的调度任务在对应延迟时间之后丢到RETRY队列)。消费时长监控告警
这个可以集成在
Client的Consumer逻辑,也可以通过RocketMQ Broker的接口做。可以通过重置offset来跳过?
感觉是部分可行,应该是可以通过设置
offset(在RocketMQ-Console上貌似是个时间)来跳过已经产生出来的重试消息,但是新投递的重试消息是先投递到延迟队列(SCHEDULE_TOPIC_XXXX)上的,也就是说此时可能对应的消息还没进入RETRY队列,所以是不是设置会无效?其他
消费实例并发上下线时的rebalance是否存在问题?
从源代码看感觉上应该是可能存在并发问题的,我指的是不同消费实例之间,本机上不存在并发问题,因为
rebalance始终都只有一个线程在做。Broker通知过来只是唤醒对应的线程。观察下面的代码,如果是不同消费实例之间,同一时间获取的cidAll可能是不同的,那么就有可能分配出不同的结果。比如有a、b、c、d四个实例,假设c、d同时停机并几乎同时启动。那么在c启动时,
Broker通知a、b,可能a接收到通知时在线的消费实例是a、b、c,而b接收到通知时在线的消费实例是a、b、c、d。假设总共有4条MessageQueue,并且是按照默认的平均分配策略的话,a给自己分配了1、2两条MessageQueue,而b给自己分配了2这条MessageQueue,这就导致了同一条MessageQueue被分配给了两个消费实例。但是由于
rebalance还有一个兜底,在没有Broker通知时,Consumer会每隔20秒做一次rebalance ,这样就可以解决这个问题。- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/rocketmq-consumer-log
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts