type
status
date
slug
summary
tags
category
icon
password
AI summary
前言
这周连续两天下午都收到线上工单告警:数据库连接池打满。这种类型的报错,对于系统稳定性的危害非常大,一收到工单就立马进行了排查,并且在第一天晚上紧急上线了一波优化,但是第二天依旧出现了同样的报错。这篇文章记录了完整的排查以及修复过程。
现象
这两天的异常基本上是一样的:每次发生都只有一个实例,且每次都是瞬时的(1-2秒内恢复)。
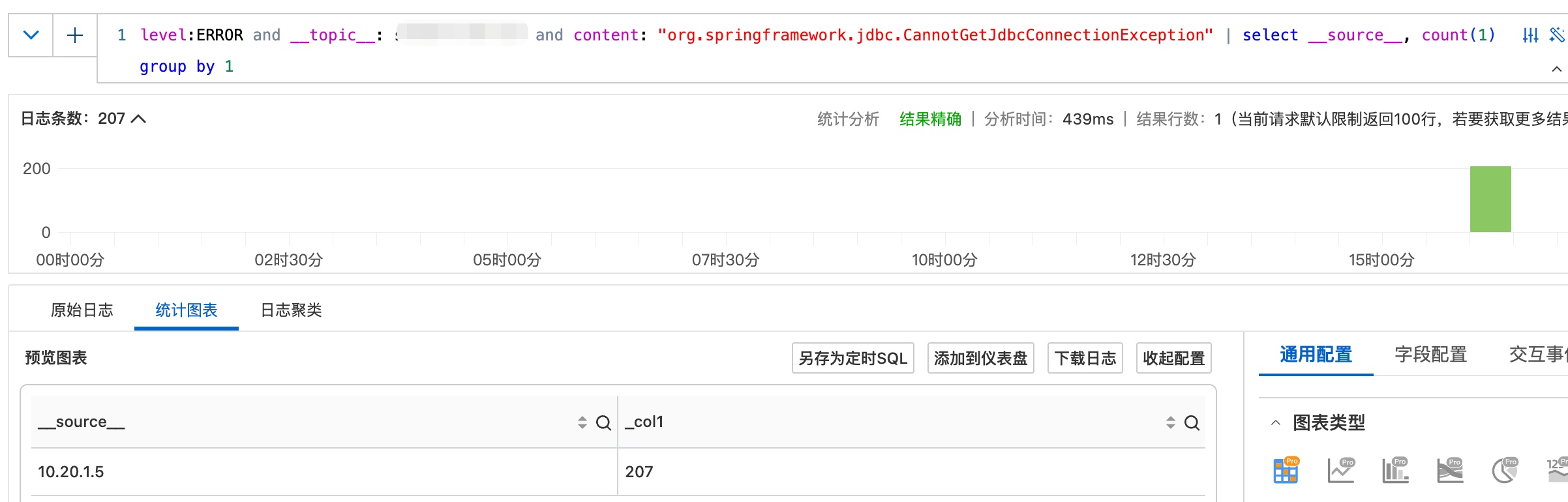
分析
数据库连接池满了,一般来说最可能有两个原因:
- 查询慢
- 请求量大
查询慢的原因可能有很多,比较常见的原因可能是:网络慢、SQL执行慢、Java应用发生了STW、应用CPU负载高等等,这里就不一一枚举了。
废话不多说,我们直接看看当时的请求量和RT:
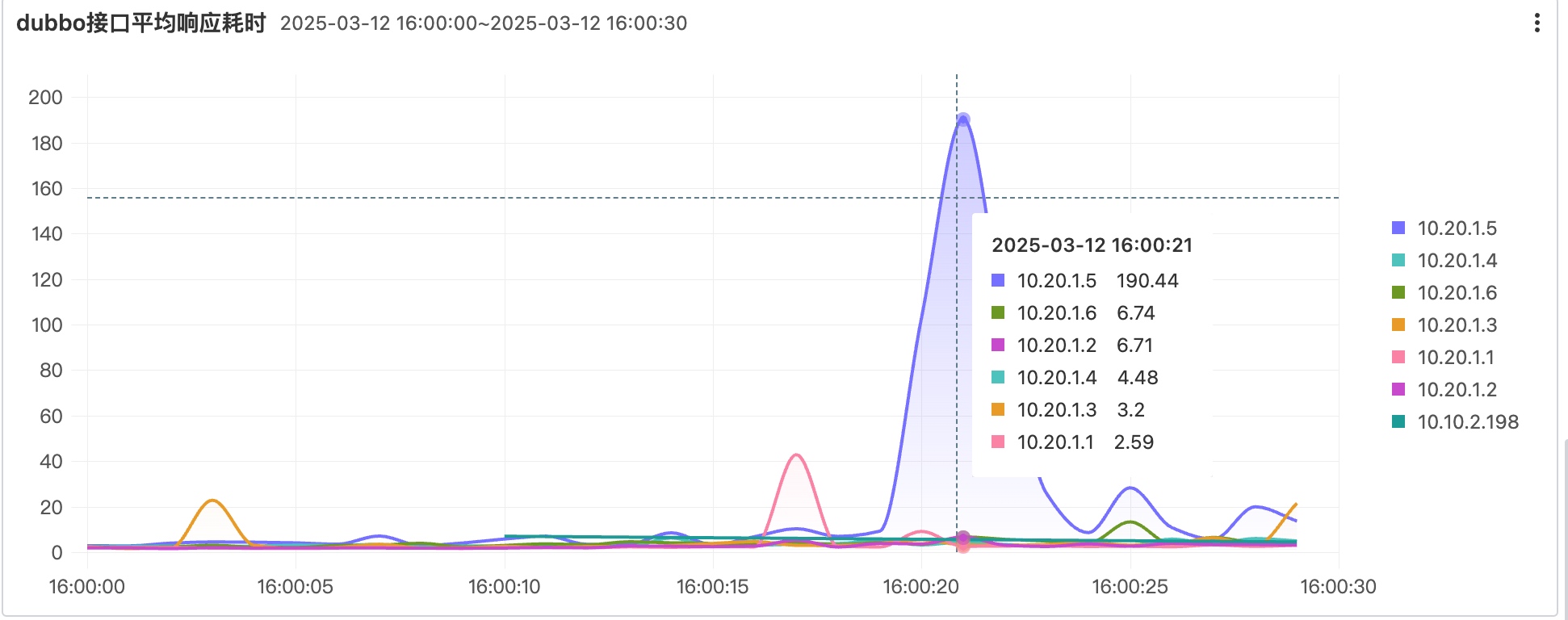
可以很明显的看到,问题实例
10.20.1.5 的RT比其他实例都要高得多。我们找到那个时间点最耗时的几个请求来跟踪一下看看: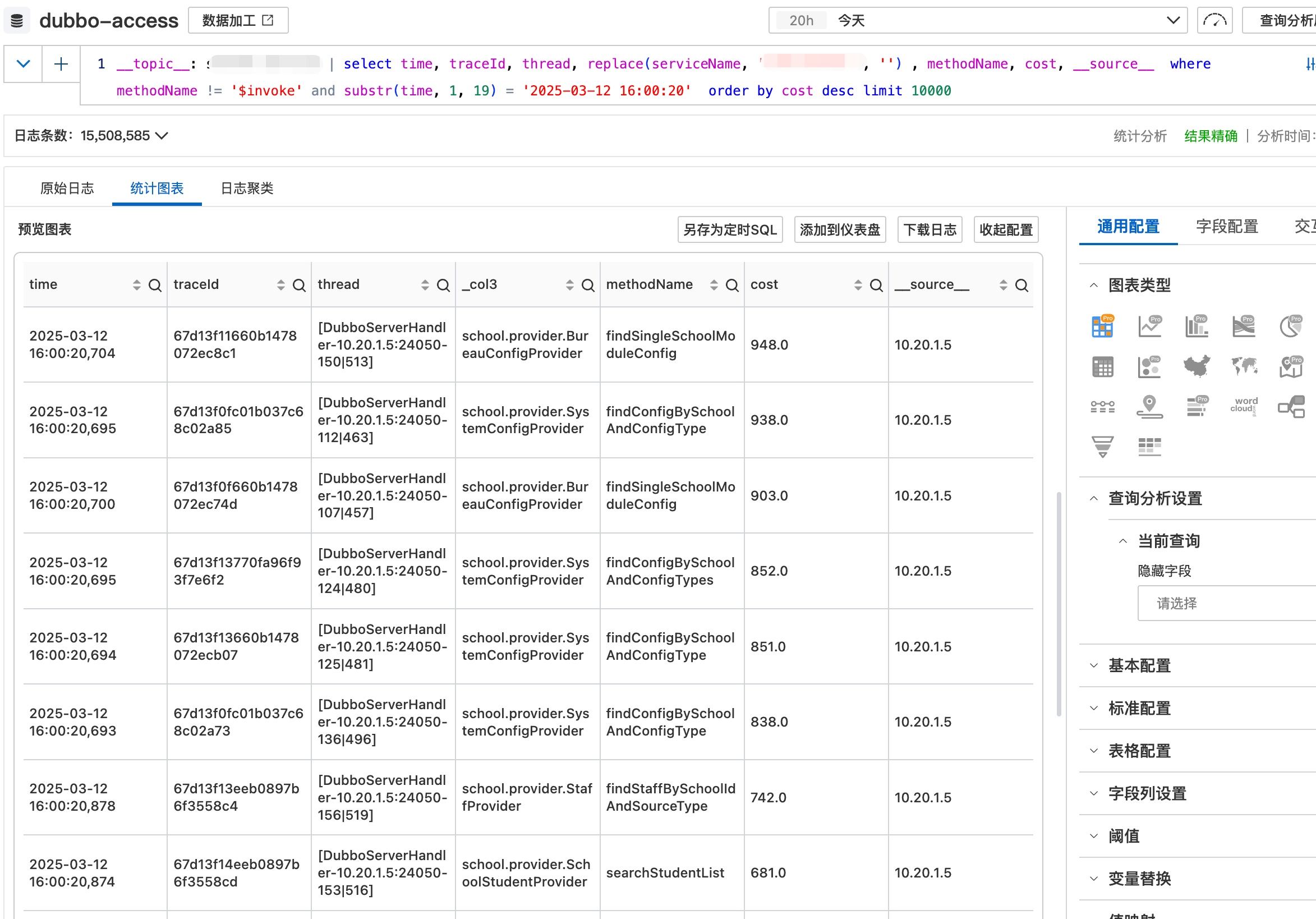
下面就是这几个请求耗时点的排查,几乎都卡在数据库查询上:
不过这几个查询在数据库里的查询时间都不慢,有两个证据:
- 数据库里我们是300ms的慢查阈值,如果是慢查,在应用日志里会打印
queryWasSlowOnServer,很显然这里没有,说明在数据库里的执行时间是小于300ms的
- 我们从阿里云RDS的审计日志里找到了对应的SQL,发现执行时间非常短

并且由于这段耗时是在mysql-driver层面打印的,两行之间基本就是发请求到mysql查询,所以问题应该不在我们自己的代码层面。那可能的原因是:
- 网络耗时
- 应用STW
- 负载高导致无法获得CPU
并且你可以看到,上面的日志最终打印出来的时间几乎都是在
16:00:20,694。那么第一个值得怀疑的就是STW,我们来看看当时的GC日志:在
16:00:19.870~16:00:20确实进行一次Minor GC,耗时246ms,不过这个和800+ms的耗时中间还差了500-600ms呢。又看了一眼机器的负载,发现当时的负载也确实很高:机器的整体CPU利用率基本都是60+,并且这还是采样得到的,按照经验来说,应该远小于瞬时的高点。1分钟负载也达到了20.78。并且这台机器是8C64G,20远大于8,意味着当时这台机器的压力确实很大,并且主要瓶颈是在CPU上。从监控上并看不出明显的网络抖动。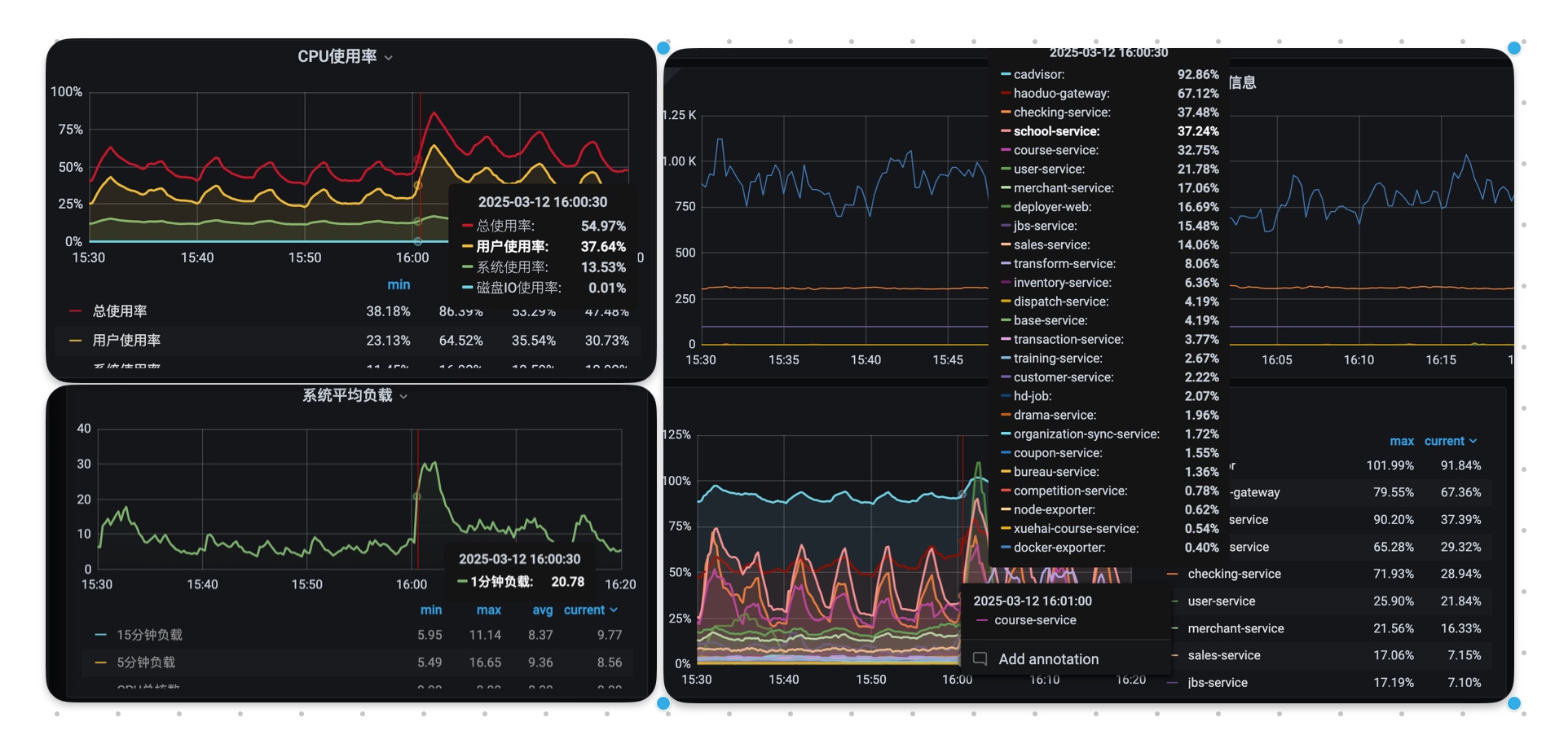
那是不是存在这么一种可能性:
- 应用发生Minor GC,业务线程全部被挂起,GC线程耗时246ms,完成Minor GC。这个Minor GC的耗时较长可能也受了当时负载高的影响,变慢了
- Minor GC完成之后,业务线程被唤醒,但是机器负载太高,导致线程获得CPU调度的延时变高,达到了几百毫秒
那么CPU的调度延时有没有可能达到500-600毫秒这个量级,我请教了
Grok 3,看看它是怎么说的:
- 如果CPU使用率接近100%,运行队列长度(run queue)可能达到12(20 - 8),线程停顿几百毫秒很可能是CPU资源紧张、调度延迟导致的。
- 建议用 vmstat 或 sar -q 进一步确认CPU使用率和运行队列长度。
看起来是存在这种可能性的,并且我也问了
Grok 3 如何进一步证实:前面两种都是每秒输出实时的数据,运行一段时间抓到
- 最高的
run-sz大概有80+
us和sy最高有96,CPU几乎接近打满
这比graphna上看到的数值要高得多,进一步说明了机器的负载很高。
第三种方式我也试了,最终采样一段时间之后,找到最大的CPU调度延迟是接近100ms,但是这并不是对应了CPU使用率最高的点,并且我在应用里也找不到对应的延迟。感觉没有得到非常满意的答案,这里记录一下过程中的问题:
- 日志里记录的时间戳相对于系统启动时间,但是通过
uptime -s加上对应的时间戳得到的时间点和真实的时间点差了7-8分钟。这样更增加了找到延时线程的位置了。
但是从文件的最后修改时间来看,是15:31:10,应该是和最后一条perf记录的时间接近。如果说成立的话,那么可以按照下面这个关系换算。
- 日志里记录的线程名称只有15个字符,这应该也不仅仅是
perf sched的问题,系统上各种地方查看线程名称都只显示15个字符,而我们的Dubbo服务线程只能显示到DubboServerHand,根本就看不出来具体是哪一个,囧。想通过jstack里的线程id去找,但是在宿主机里又没法直接jstack,在容器里jstack出来的又是容器里的线程id。arthas也没法在宿主机上使用。
- CPU调度延时一定会体现到我们应用日志里吗?感觉也不一定,除非是在我们记录两个时间差窗口内的延时。比如在请求就绪但是还没进入web请求计时器之前的调度延时,应该就不会体现
另外,我觉得人肉采集这种方式很难抓到问题点,我又问
Grok 3有没有更高效的抓取方式:使用 bpftrace:脚本示例(针对 PID 25916 的所有线程):运行后,实时输出超过 200ms 的延迟事件。
不过这个
bpftrace我还并没有尝试。优化
虽然说没有得到确定性的结论,但我暂时也想不到还有什么其他的可能性了。有时间的话可以继续做实验来验证。不过这不妨碍我们进行优化:主要的目的就是降低负载,虽然也可以通过扩容来进行,不过优先还是通过技术手段,给公司省点钱。
请求量高
我们通过阿里云上的请求日志来看看请求量和耗时情况:
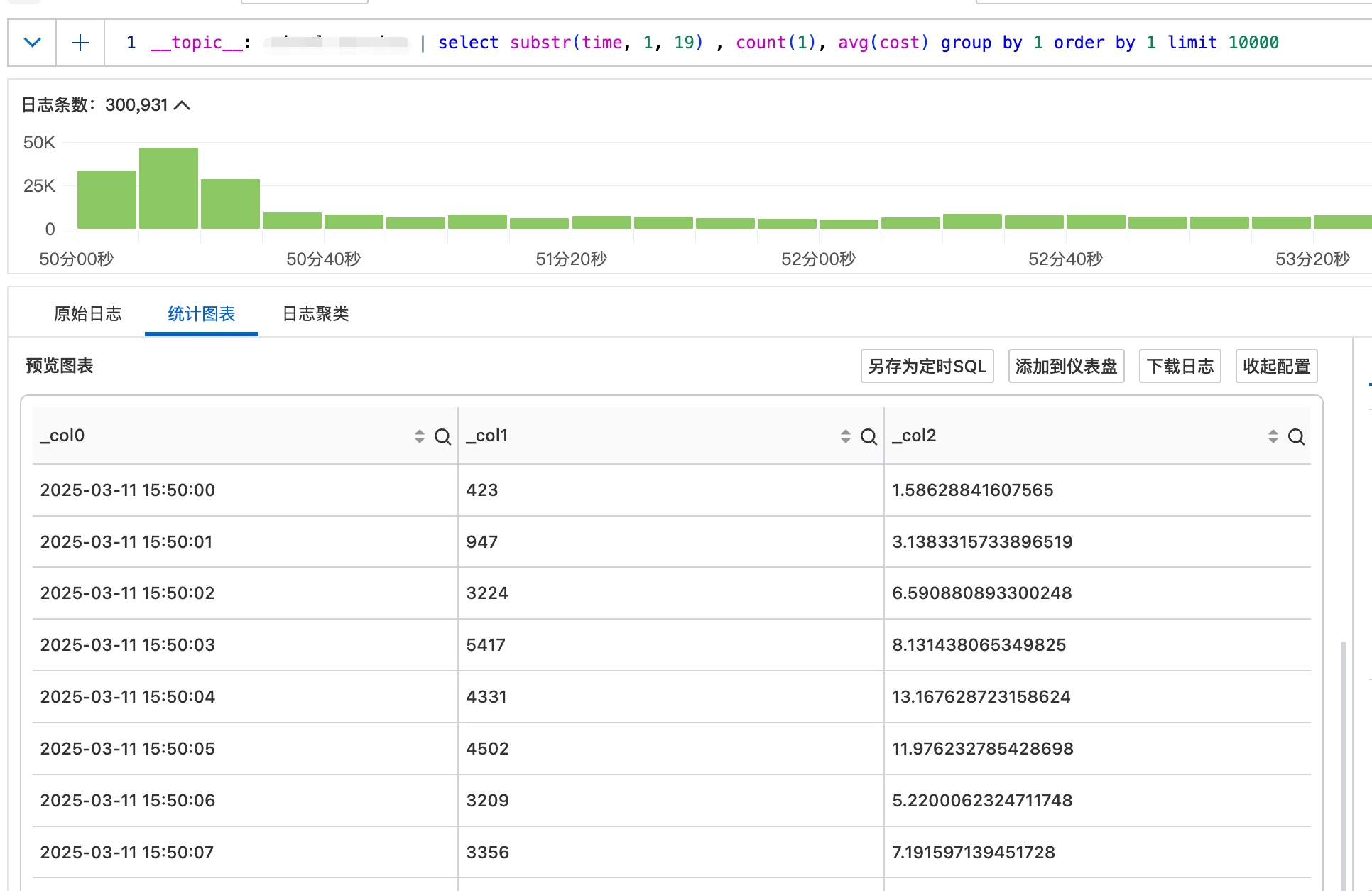
我们直接找请求量最高那个时间点
15:50:03的调用方及方法分布: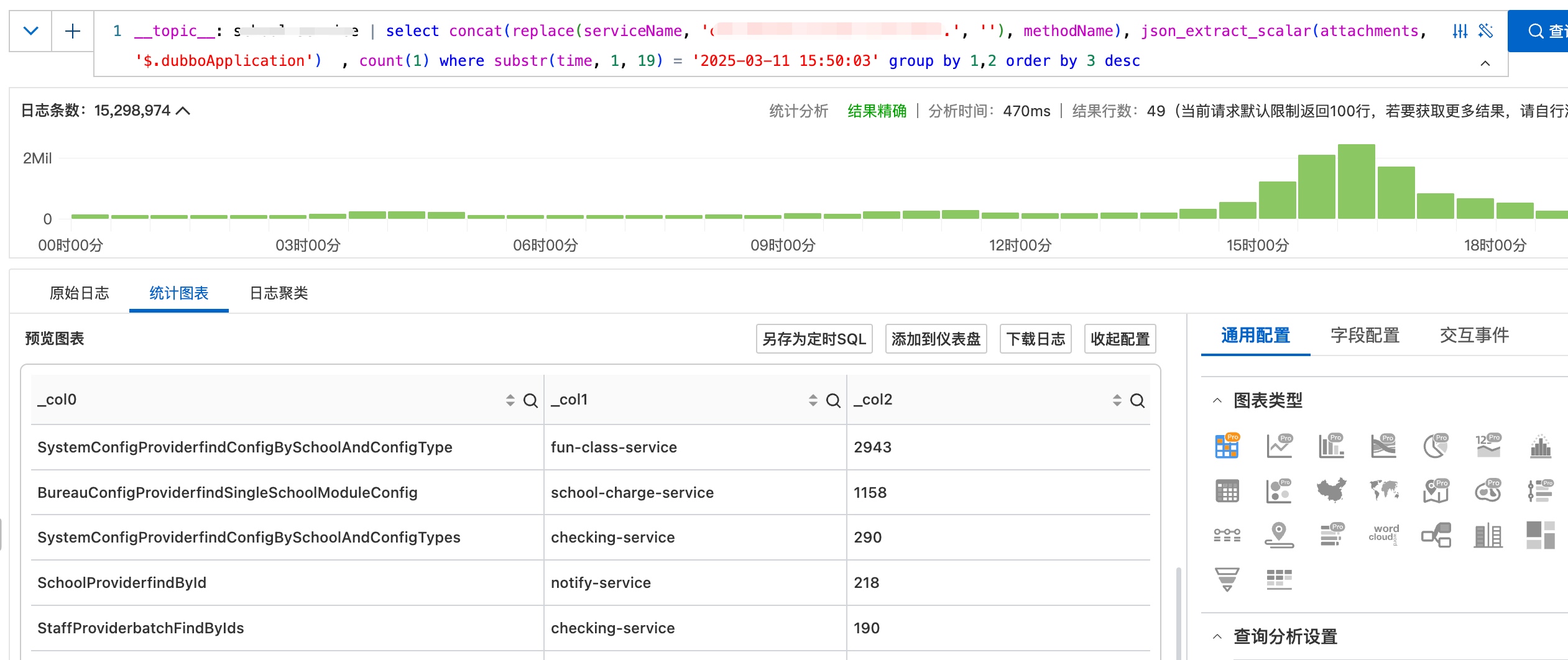
可以看到,前两个服务明显看起来不太正常。于是我找到几个请求跟踪了一下,发现调用链路的源头都是消费【学生考勤状态变更】类型的RocketMQ消息。
这里先简单介绍一下业务背景:我们是一家做课后服务的公司,每天会产生大量的学生考勤数据(千万级别)。这里的考勤分为两种,有一部分学校的老师每天会做手动点名,但是有些学校希望有自动考勤的功能:
如果学生没有请假,默认就是出勤。
这个我们是通过自研的延迟消息来实现的,延迟消息的调度时间集中在学校下课的时间点。到了这个时间点,会有一大批的学生考勤数据会被自动修改成出勤,这也就是这里同时产生大量消息的原因。
既然找到了问题,这里有两个优化点:
- 把消息发送的速率降下来因为这种自动点名对于时间点的精确度要求不高
- 看高频接口有没有可以优化的地方
降高频消息发送速率
我们看看原来的发送方式:
修改的方式也很简单:
- 不用RocketMQ批量发送的API
- 循环单条消息发送,增加间隔时间
关于RocketMQ批量发送消息的API,这里提一个坑:如果批量发消息,那么这批消息是会被发送到同一个MessageQueue里的,所以在批量消息过大的情况下,可能导致消息无法负载均衡,会让下游消费实例压力不均。
这个sleep时间应该如何考量呢?可以结合系统的吞吐能力来计算。首先,由于这里是一个RocketMQ消费者,默认单个消费实例的消费线程是20条,我们线上部署了4个实例,那么总共就是80条线程在消费。按照全部跑满来计算,那么我这里sleep 200ms,相当于就是1条线程每秒能发送5条消息,再乘以80条线程,总共就是400条消息/秒。
我们还要再拿一下今天下午的日志来做一下对比,不过RocketMQ消息发送日志是如下格式,不太容易提取。
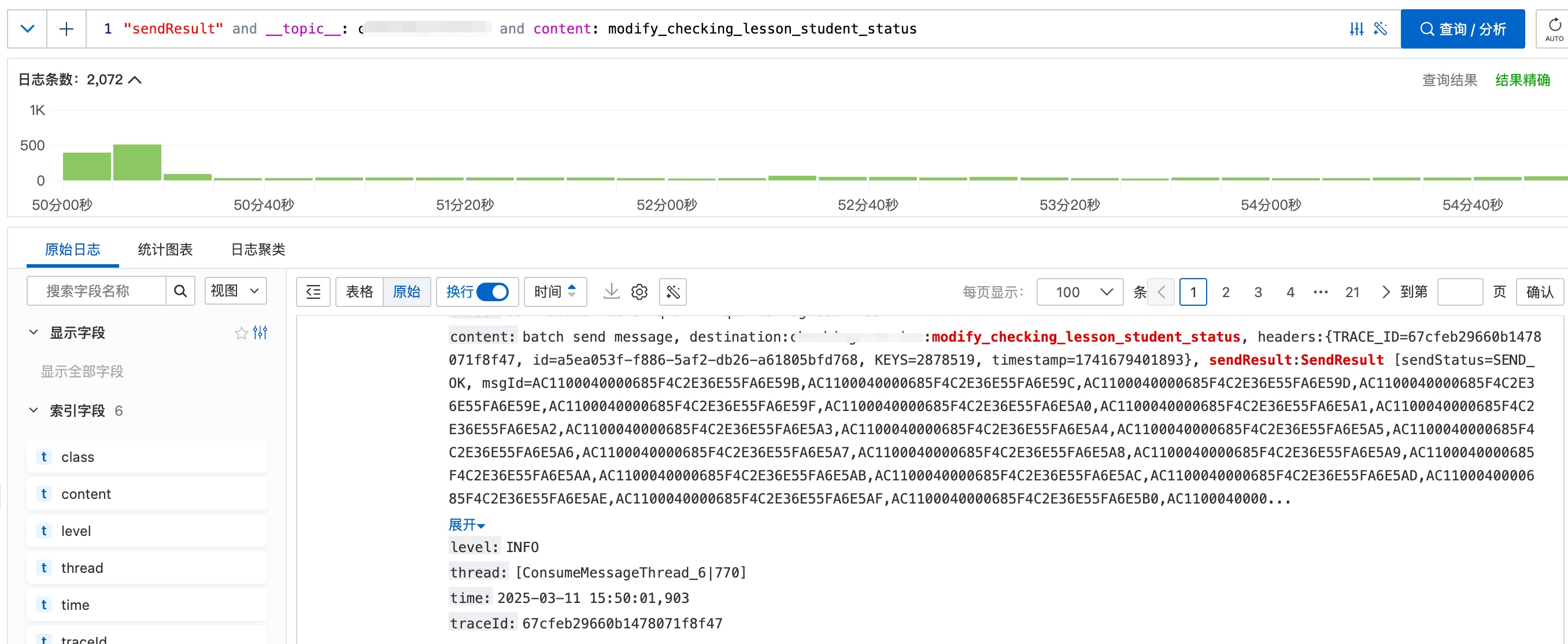
这个时候我们可以借助
Grok来帮我们写代码:于是得到的如下的python代码:
一次即通过。输出的结果如下:
那我们400条/秒的设定比原峰值降低了80%以上,目测应该能达到一个比较好的效果。
优化高频接口
查询到高频接口是消费线程反查学校的一些基本信息以及学校维度的一些配置,学校维度基本信息提供了一个全字段的查询接口,这里可以精简。虽然这个优化动作看起来很普通,但是对于高频接口,效果会非常显著。
定时任务时间调整
当时除了上面说的高频消息导致的应用CPU上升之外,还有两个应用CPU升高比较明显。查询日志之后发现,是定时调度的任务,每天16点开始运行。
其中,deployer-web有3个耗时比较长的定时任务进来。
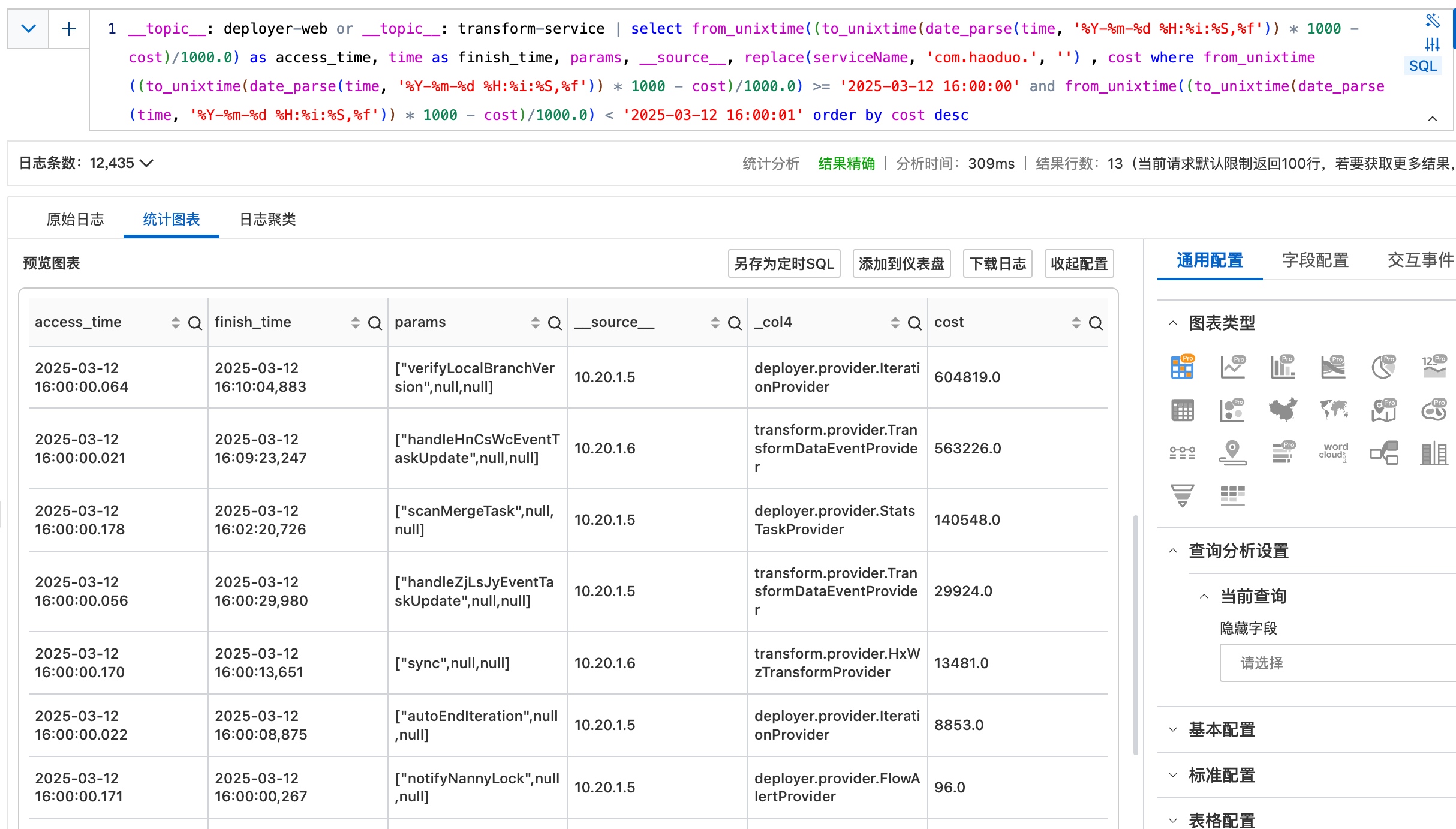
由于我们的业务特性,课后服务(15:30~17:30)是我们的业务高峰,所以这几个无关紧要的任务我直接调整在15-18点之间不执行。
总结
去年差不多同样的时候也碰到了数据库连接池打满的情况,不过当时的原因是:连接池里的可用连接同时失效,并且当时创建新连接耗时都比较长,最终导致短时间内无连接可用。
现在回看这篇文章,发现好像没有说明当时创建新连接耗时长的原因。可能是网络问题,也可能是STW。不知道当时为什么没写上,现在也没有现场日志了,没法还原了。可惜可惜~
不过今天这个问题倒是采用了不少手段去探查,虽然还没有得到明确的结论,但是也算是有一些收获!
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/db-connection-pool-exhausted
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts
