type
status
date
slug
summary
tags
category
icon
password
AI summary
现象
在做线上巡检的时候,发现某个服务checking-service的4台实例里其中有一台的cpu使用率比其他三台明显要高很多
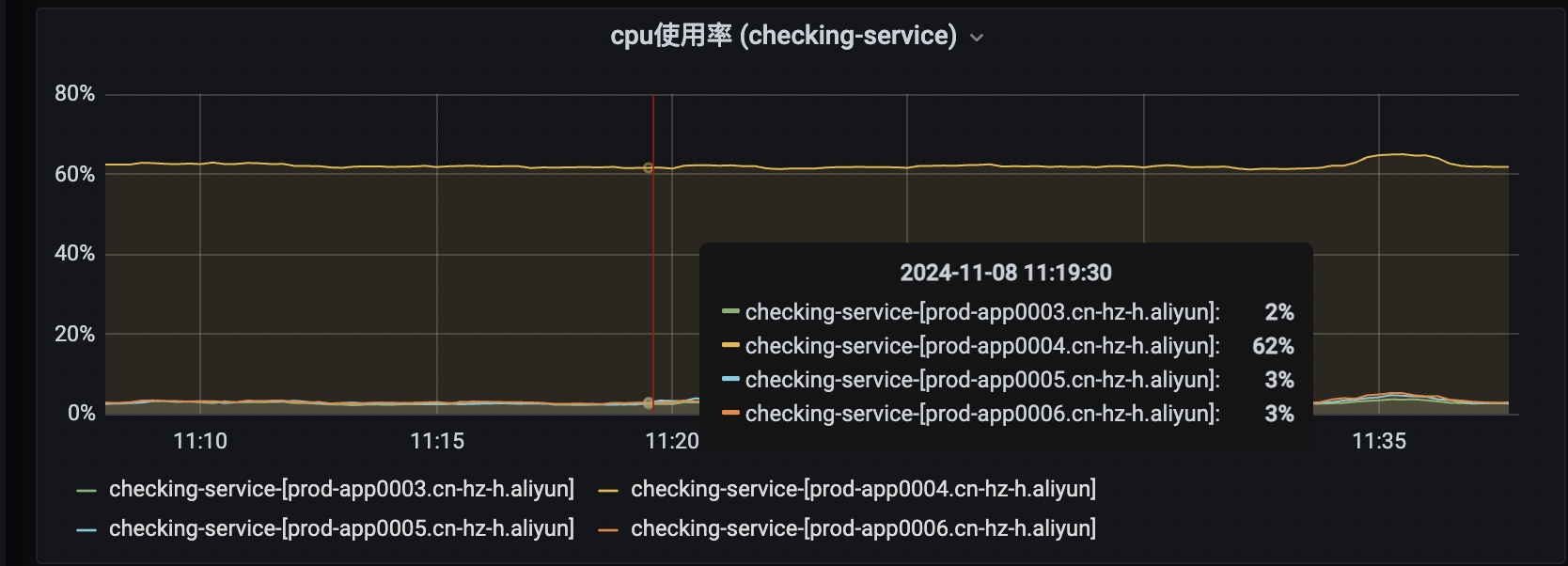
结合其他指标观察,发现进出带宽也明显比其他实例要高

排查
排查思路有两种:
- 从带宽入手
- 从cpu使用率入手
从带宽入手
我们使用
iftop命令来看看带宽使用情况
可以看到,主要的流量来自于和
10.10.1.99的通信。10.10.1.99是我们的mysql数据库,所以可能是查询数据库出现了死循环。我们再通过
tcpdump命令抓包看看具体的SQL大概是什么从中找到一些关键的sql
通过这个SQL大致也能定位到问题代码。另外由于我们的阿里云的rds开了审计日志,所以也可以从数据库的审计日志上筛选出对应机器ip对应的SQL。
从cpu使用率入手
传统top+jstack方法定位
我们还可以从cpu使用率入手,通过命令
top -H -p1查看cpu使用率高的线程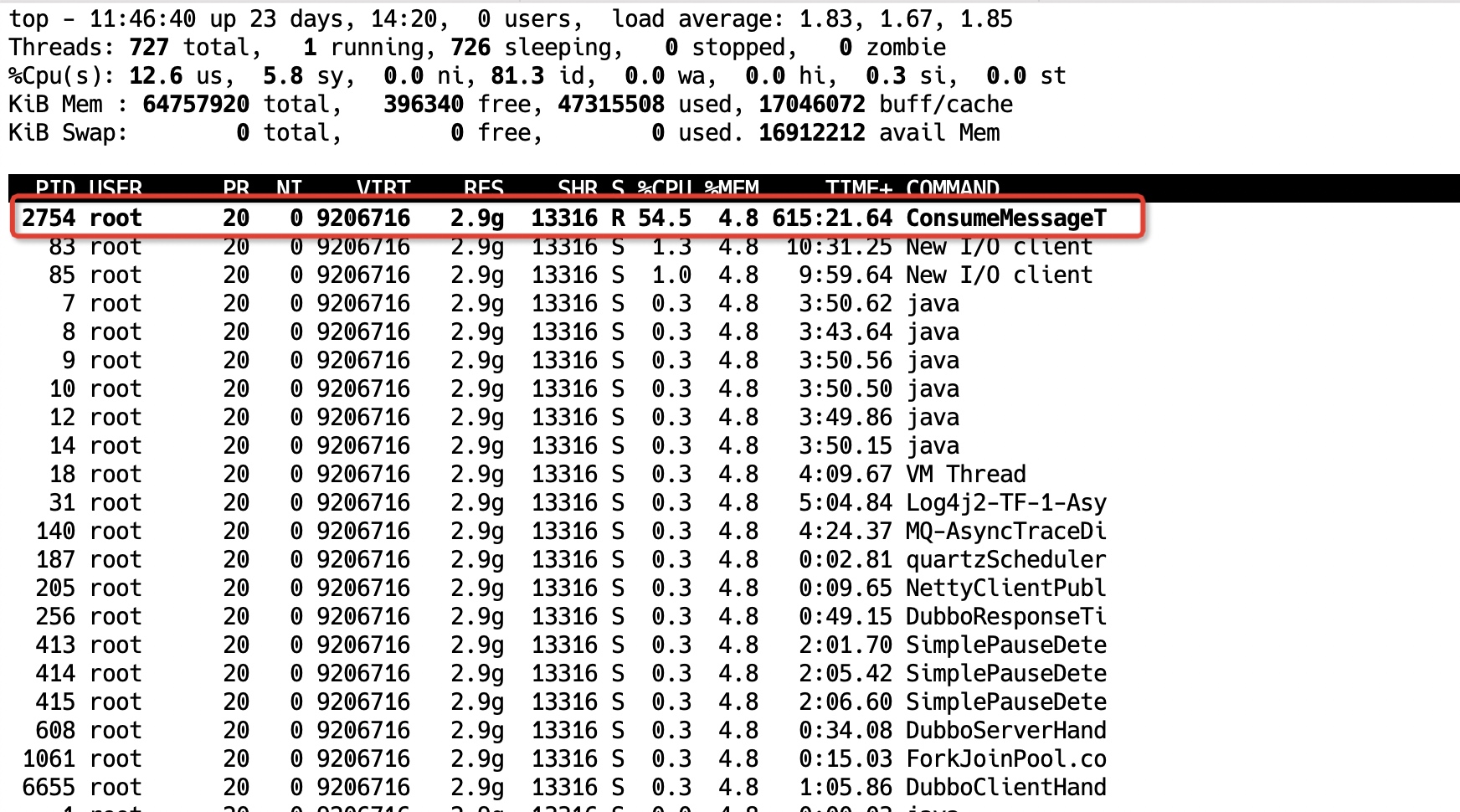
发现
pid=2754这个线程的使用率较高,从COMMAND看应该是个RocketMQ的消费线程。根据pid转换成16进制:根据pid在jstack里定位到对应的线程(
nid=0xac2):arthas定位
另外也可以使用arthas来定位,thread命令默认就是按照cpu使用率从高到底排序的

用
thread -n 1可以直接打印出最耗cpu的线程堆栈修复
找到对应的问题代码,是在基于最小id分页遍历取数的时候,没有更新每次查询里的最小id
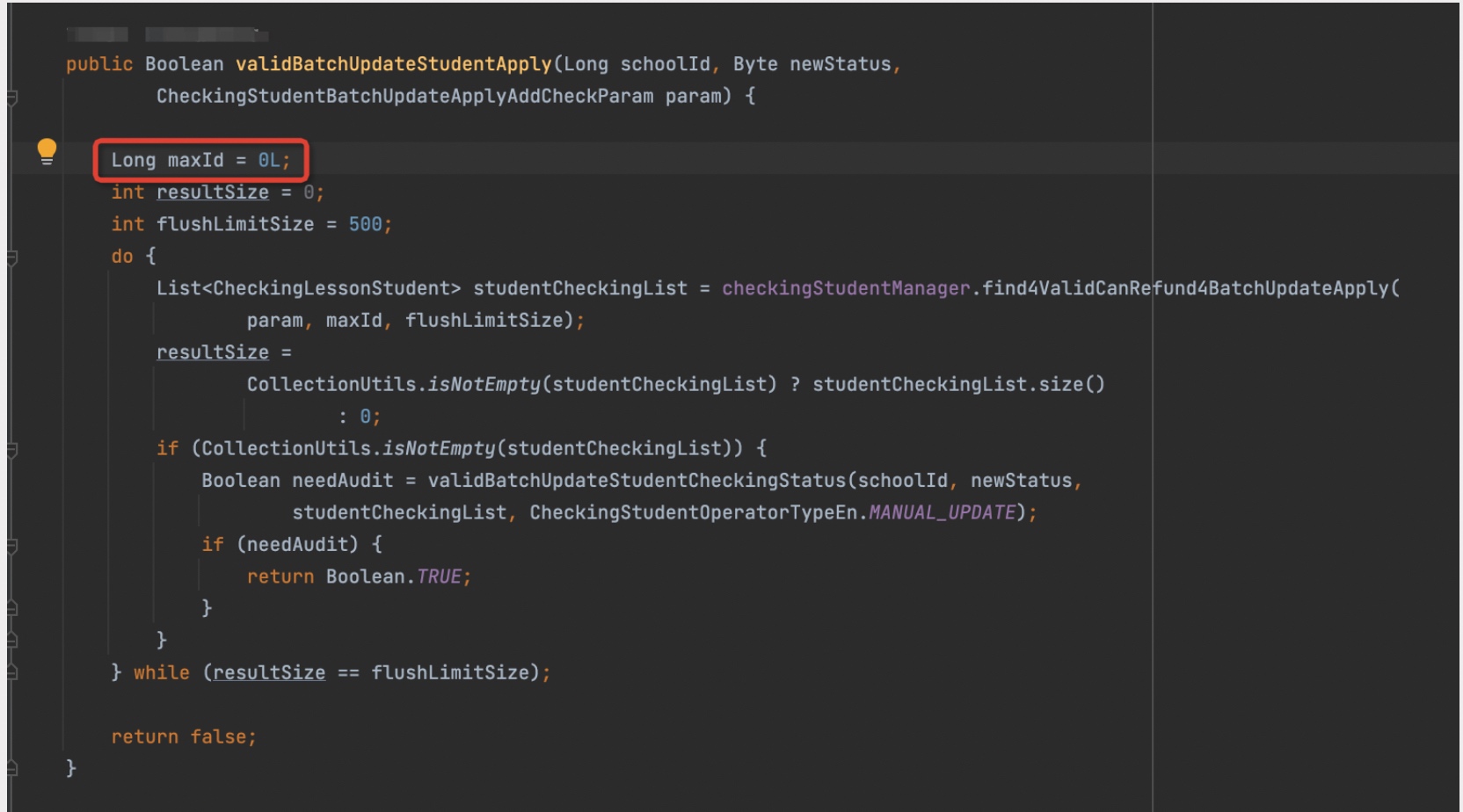
这里有2个问题:
- maxId更新
- 查询语句未按照id升序
此类分页查询已经是线上的第N次问题了,我们自己写了一个分页框架来规避此类问题。
参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/high-cpu-usage-with-high-brandwidth-usage-probolem
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
