type
status
date
slug
summary
tags
category
icon
password
AI summary
背景
之前为了实现大数据量的导入/导出,提供了一个模板工具类,是通过streaming流式查询的方式从数据库里查数据,并且执行导出。但是部门小伙伴在使用过程中,却偶然碰到了如下的问题:
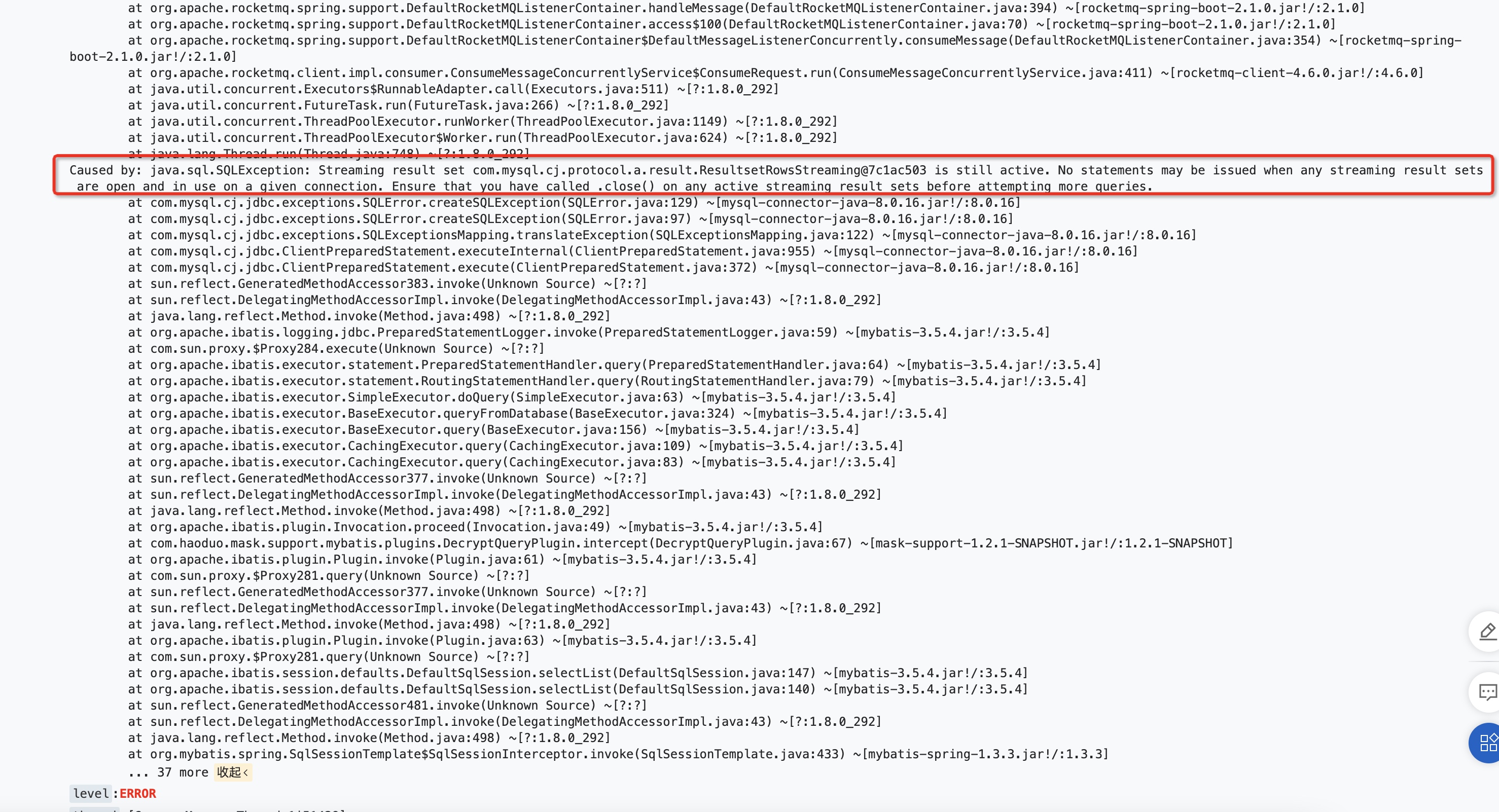
问题分析
这个异常之前我就碰到过,印象里是因为当时执行流式查询的语句没有加事务,导致查询方法调用结束后,数据库连接(connection)就被归还到连接池里了,但此时该连接打开的流式查询并没有把数据消费完,所以它还不能被复用。那么当这个连接后续被取出执行SQL时就会报上述的错误了。因为执行流式查询的过程中,连接必须保持住,因为它的实现是通过TCP连接的滑动窗口来做的。
不过加上事务之后,这个问题应该就得到解决了,怎么此时又报出了这个错误呢?我们先来看看代码:
AbstractCursorExporter
AbstractCursorExporter,主要负责处理流式查询相关的逻辑
AbstractBatchHandleExporter
我们再来看看它的抽象父类,AbstractBatchHandleExporter
再往上的抽象父类这里就不贴代码了,简单描述一下整体的导出流程
- 打开事务
- 执行流式查询
- 批量获取流式查询结果,500个为一批进行处理
- 处理过程大致分为
- map 转换
- mask 脱敏
- 导出成excel文件
问题代码
看到这里,其实已经大致猜到问题原因了:整个流式查询是被包在了事务里的,而map方法是在每一批数据处理的过程中调用的,进而也被包在了事务里,而此时的连接正在进行流式查询,没法再进行其他的查询。所以就报错了。
仔细看了一下报错,其实和之前报这个错是不太一样的,之前的报错是不同的线程,而此时报错和流式查询是同一个线程。那么也印证了这一点。
解决方案
既然知道了问题的原因,那么怎么来解决这个问题呢?很容易想到,我后续的查询不用到当前这个connection不就行了么?但是查询用哪个connection这个事好像不是我们手动指定的。怎么在同一个事务中用不同的连接进行数据库操作呢?这里就涉及到事务传播机制的内容了。感兴趣的同学可以看这篇文章 http://www.asznl.com/post/125
我们直接上结论,在进行map操作之前,我们创建1个新事务(并非数据库的事务),事务传播级别设置成not_supported,让后续的数据库查询语句不走外层的事务,也就是会重新拿一个connection去执行。map完成之后,再把内层事务提交掉。
疑问解答
这里还有值得注意的问题需要重点解答一下
为什么dev/qa都是正常的,并且pre和prod之前也有成功导出的请求
因为之前请求的数据量太少,都没有超过一个批次的数量——500。所以每次都是把流式查询连接里的数据取完了之后才进行的map,也就没有触发问题。执行流式查询的connection可复用的条件有2个:
- 流式查询结果集的元素被消费完
- 流式查询被提交或关闭
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/a-trap-of-mysql-streaming-query
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!