type
status
date
slug
summary
tags
category
icon
password
AI summary
背景
大数据量的导入/导出功能,我们使用RocketMQ做了异步化处理。具体流程是:
- 用户向任务中心提交导入/导出任务,提交成功即返回
- 任务插入时伴随发出任务生成的事务消息
- 业务服务监听任务生成消息,处理自己的任务类型,完成导入/导出逻辑
- 过程中实时汇报进度给任务中心、完成之后提交最终产物
而近期新上的某个导出功能,在灰发环境测试的时候,发现在数据量较大的场景下,消费时间很长(超过40分钟),并且由于最终导出生成的文件很大(超过8G),最终在上传产物到oss时失败了(上传时有大小限制5G),导致消费失败。
而消费失败的消息在RocketMQ默认的重试机制下会重试16次。不过,我们跟踪了一下消费日志,发现并没有那么简单。
本文基于RocketMQ 4.6.0版本进行分析
日志分析
日志里的问题
下面就来看看我们从消费日志里发现了什么。我从日志里提炼了下面的表格。
消费开始时间 | 消费结束时间 | 重试消费次数 | 消费者实例ip |
2024/3/6 19:07:00 | 2024/3/6 19:48:05 | 0 | 10.11.25.28 |
2024/3/6 19:48:15 | ㅤ | 1 | 10.11.25.28 |
2024/3/6 20:10:00 | ㅤ | 1 | 10.11.19.167 |
2024/3/6 20:10:56 | ㅤ | 1 | 10.11.25.28 |
2024/3/6 20:16:11 | 2024/3/6 20:56:51 | 1 | 10.11.19.167 |
2024/3/6 20:17:06 | 2024/3/6 20:56:32 | 1 | 10.11.25.28 |
2024/3/6 20:57:02 | 2024/3/6 21:40:25 | 2 | 10.11.25.28 |
2024/3/6 21:41:25 | 2024/3/6 22:24:06 | 3 | 10.11.25.28 |
2024/3/6 22:26:06 | 2024/3/6 23:07:22 | 4 | 10.11.25.28 |
… | … | … | … |
相信你也看出了其中比较诡异的两点:
- 有3次消费没有结束
reconsumeTimes=1的重试消息被消费了5次之多
消费流程分析
下面我们逐次分析消费流程:
第一条属于正常消费,但是最终由于产物过大,上传oss失败导致消费失败。RocketMQ Client对于消费失败的消息,会重新投递一条重试消息到Broker。
第二条就是第一条消费失败后投递产生的消息,和第一次消费结束间隔了10s,符合预期,不过没有找到消费结束的日志。
而第三条到第六条日志,就更奇怪了。
reconsumeTimes 都是1并且消费的间隔时间也没有规律。我们从
RocketMQ Console上拉了一份这个consumerGroup对应的retry topic下的消息,也侧面印证了中间几次并不是消费的新消息,感觉是重复消费的同一条消息(重复消费那条reconsumeTimes=1的消息)消息ID | tag | 产生时间 |
0A0B14340000685F4C2E1DD9E8880000 | lesson-feedback-img-export | 2024/3/6 19:48:15 |
0A0B14340000685F4C2E1DD9E8880000 | lesson-feedback-img-export | 2024/3/6 20:57:02 |
0A0B14340000685F4C2E1DD9E8880000 | lesson-feedback-img-export | 2024/3/6 21:41:25 |
0A0B14340000685F4C2E1DD9E8880000 | lesson-feedback-img-export | 2024/3/6 22:26:06 |
0A0B14340000685F4C2E1DD9E8880000 | lesson-feedback-img-export | 2024/3/6 23:10:22 |
... | ... | ... |
是不是当时紧急调整导出逻辑之后发布导致的?我们拉了当时的发布记录:
发布批次 | 机器IP | 启动时间 |
第一次 | 10.11.25.28 | 2024/3/6 20:10:07 |
第一次 | 10.11.19.167 | 2024/3/6 20:12:27 |
第二次 | 10.11.19.167 | 2024/3/6 20:14:33 |
第二次 | 10.11.25.28 | 2024/3/6 20:16:18 |
确实是有两次发布,每次发布包含两台实例。看时间点和前面的基本能对上。我们知道对于集群消费,每次消费组里有实例上线或者下线,Broker上都会记录日志。于是我们又从 Broker的日志上得到了佐证:
日志可能有些杂乱了,我们还是列一张类似前面的时间表格来更加清晰的呈现:
消费实例上下线时间 | 本实例 | 类型 | 当前在线实例 | 分配到重试队列的实例 |
2024/3/6 20:10:00 | 10.11.25.28 | 下线 | 10.11.19.167 | 10.11.19.167 |
2024/3/6 20:10:54 | 10.11.25.28 | 上线 | 10.11.25.28、10.11.19.167 | 10.11.25.28 |
2024/3/6 20:12:20 | 10.11.19.167 | 下线 | 10.11.25.28 | 10.11.25.28 |
2024/3/6 20:13:19 | 10.11.19.167 | 上线 | 10.11.25.28、10.11.19.167 | 10.11.25.28 |
2024/3/6 20:14:26 | 10.11.19.167 | 下线 | 10.11.25.28 | 10.11.25.28 |
2024/3/6 20:15:25 | 10.11.19.167 | 上线 | 10.11.25.28、10.11.19.167 | 10.11.19.167 |
2024/3/6 20:16:11 | 10.11.25.28 | 下线 | 10.11.19.167 | 10.11.19.167 |
2024/3/6 20:17:05 | 10.11.25.28 | 上线 | 10.11.25.28、10.11.19.167 | 10.11.25.28 |
… | ㅤ | … | … | … |
从broker日志里是看不出后面两列的信息的,这是我们结合实际情况以及源代码推演出来的。
场景回溯
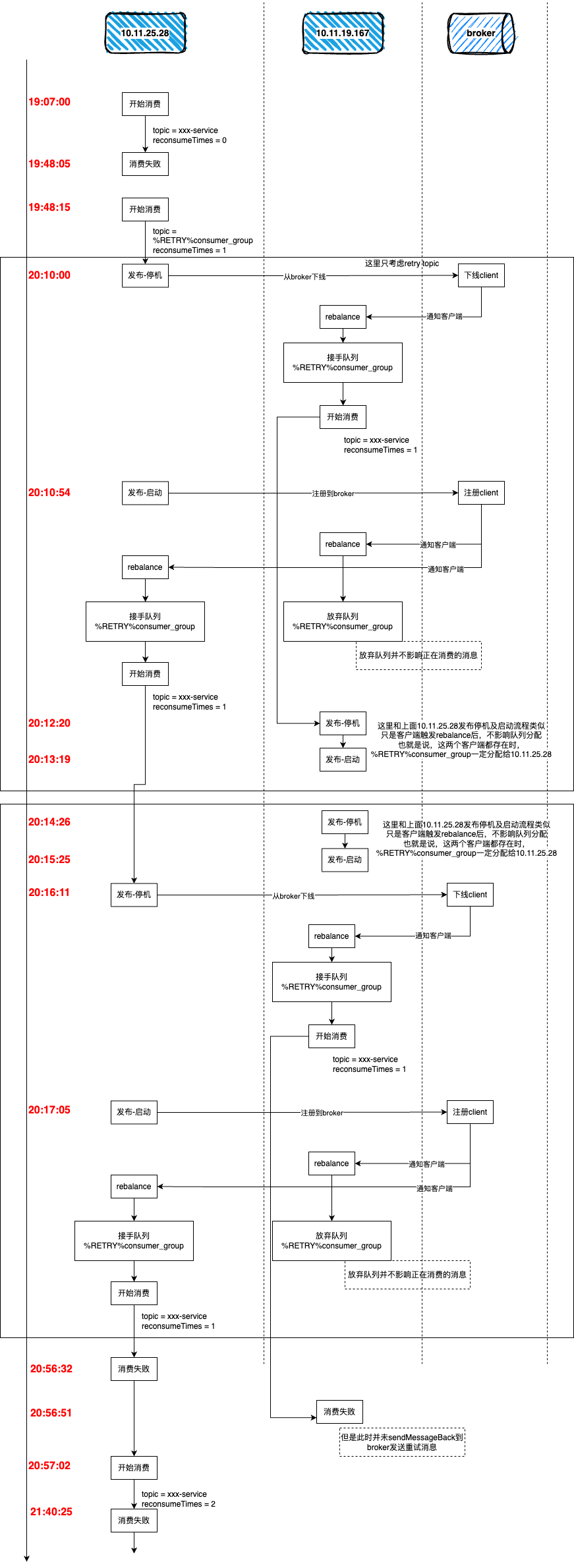
至此,我们可以回溯出整个问题场景。这里分成文字版和图示版,建议两个版本结合一起看,可以更好的理解。当然也可以先看图示有个直观概念,再来看文字版。
文字版
- 正常消费,耗时40分钟左右,由于产物过大上传oss失败,导致消费失败。此时client正常向broker投递重试消息,重试消息的topic为retry topic。
- 第一次重试消费,此时retry队列由
10.11.25.28消费。消费过程中由于发布第一次代码优化,中断了消费逻辑。此时reconsumeTimes=1的消息未被ack(第1次)
- 由于是
10.11.25.28先发布,发布第一步先要停机,停机又触发了自身从Broker下线,导致retry队列被分配给10.11.19.167。此时reconsumeTimes= 1的消息被10.11.19.167消费(第2次)
- 紧接着,
10.11.25.28启动成功,此时又会去Broker上注册,导致retry队列被分配给了自己。此时reconsumeTimes=1的消息被10.11.25.28消费(第3次)
- 轮到
10.11.19.167发布,也是先停机,中断了消费逻辑,然后去Broker下线,但此时retry队列本身就不是自己在消费的,所以没有变化。此时reconsumeTimes= 1的消息同样未被ack。
- 第二次发布,这次先发的是
10.11.19.167,此时retry队列本身就不是自己在消费的,所以没有变化。
- 轮到
10.11.25.28发布,先停机,导致retry队列被分配给10.11.19.167。此时消息又一次被10.11.19.167消费(第4次)
- 紧接着,
10.11.25.28停机,导致retry队列被分配给自己。此时消息又一次被10.11.25.28消费(第5次)
有两点值得注意的是:
- 当retry队列重新分配之后,之前正在消费中的消息并不会受到影响。比如,最后一次虽然队列被分配给了
10.11.25.28,但是10.11.19.167在第7步中消费到的消息还在继续执行整个消费流程。只不过,在消费结束的时候,消费组会识别出此队列并不该由自己处理,所以无论消费结果是成功和失败,client都不会再进行处理(比如失败后需要发送重试消息到broker)
- RocketMQ消费组内消费队列的分配是客户端行为,broker并不参与分配的过程。broker只是在实例上下线的时候会对整个消费组实例做广播通知。由客户端采用统一的算法去给自己分配队列。
图示版
为了大家能更直观的理解,下面还准备了一张图,以时间轴的形式展现了整个消费过程。
one more thing
记得之前看RocketMQ Client源码的时候,有一个对于消费时间过长的消息的处理,于是又去翻看了一下源代码。发现确实是有这么个机制,但是不知道为什么这里没触发。
每个消费实例启动的时候都会注册一个定时任务,根据配置的消费超时时间作为它的执行周期。主要是处理processQueue里正在消费的消息
默认的超时时间是15分钟。不过我们使用了
rocketmq-spring-boot包。这个包里增加了一些更易用的消费注解,其中有一个配置就是consumeTimeout,默认值是30000,看注释原本是想设置30s的。但是对应的定时任务的单位是分钟,所以默认变成了30000分钟,也就是500个小时,几乎不可能走到超时逻辑了。
不过,这个超时逻辑“还好”没有生效。如果生效,对于系统更是“灾难”。因为它的处理机制是,发现消费超时的消息后,并不会中断消费,而是给broker发送一条10s后的延迟“新消息”作为重试消息。这样不是给本就不富裕的家庭雪上加霜吗?最终会导致消费端消费线程全部打满或者是其他资源到瓶颈。
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/analyze-weird-rocketmq-consumer-log
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts