type
status
date
slug
summary
tags
category
icon
password
AI summary
背景
这是做分库分表改造的时候碰到的一个问题,场景是canal的全量etl功能。在表数据量较多的情况下,原生的canal是通过分页查询并利用多线程去遍历全表数据的。我们知道,这么处理肯定会存在深分页的问题,越翻到后面查询效率越低,对mysql的压力也越大。
于是我们对canal的源代码做了一些改造,改成了通过流式查询的方式遍历全量数据。这个在直连mysql的时候没有问题。但是分库分表之后,我们把数据源切换成了shardingsphere-proxy。再做全量etl,就会报错,不过不是立马报错,而是会先执行一段时间,在我的场景中,大概20w行数据之后,就开始报错了。
我们使用的shardingsphere-proxy的版本是5.1.2,下文涉及到的源代码也都是基于这个版本。
问题分析
上面的异常看起来是shardingsphere-proxy报的错误,不过在shardingsphere-proxy的日志里却找不到具体的原因,只有下面这条异常日志:
消失的异常日志
通过异常堆栈,我们可以看到是在
MySQLComQueryPacketExecutor.close()链路里爆出的异常。这个似乎和我们想象中的位置不一样,只能通过源码去解密:
上面这段源代码可以解答2个问题
- 为什么上面的异常堆栈是在close的调用链路
- 为什么真实的异常没有打印出来
我的猜测是在
commandExecutor.execute(),也就是命令执行过程中抛出了SQLException,被捕获之后并没有打印异常日志(其实什么也没做,就把异常重新throw了出来),然后走到finally块,在这里会调用commandExecutor.close()。但是在这个close过程中又报错了,前面的异常就没有机会打印出来了。准备修改一下源代码,验证我的猜想
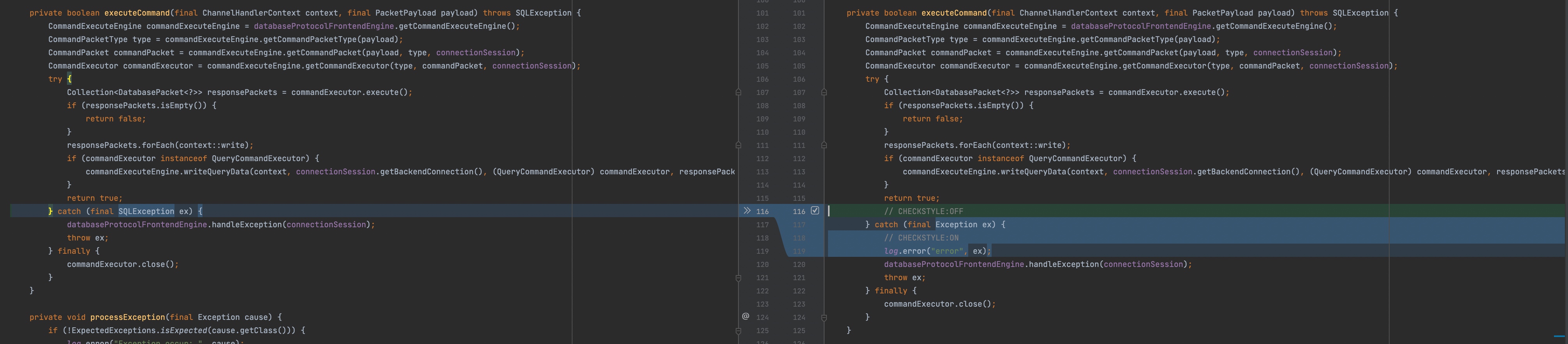
由于shardingsphere代码里使用了check-style的代码规则校验,是不允许捕获这种很宽泛的异常(比如Exception)的。所以我借鉴了代码里其他地方的做法,直接在这一行代码前后增加了声明不检查的标记。
改完之后,重新编译构建,然后替换对应的依赖包,重启shardingsphere-proxy,再执行canal的etl。canal里依然爆出之前的错误,而此时shardingsphere-proxy的日志里已经打印出了对应的异常:
这也验证了我们的猜想。那么下面,我们就要分析为什么会在执行一段时间之后报这个异常。
串用的连接
我造了1000w+的数据,尝试在本地复现这个问题,但是没有成功(这个当然是因为没有和线上保持同样的场景,因为不知道关键点是哪个,以为已经高度还原了)。
于是还是回到生产环境,我们把shardingsphere-proxy和底层mysql的交互日志都打开(这个是通过自定义mysql-connector-intercepter来实现的)。然后再执行一次etl,此时有对应的查询日志,但是奇怪的是,少了对应的
SET net_write_timeout命令的日志。mysql流式查询默认都会先发送一条SET net_write_timeout,除非你手动把netTimeoutForStreamingResults参数设置为0。而在我们的场景里是没有手动设置netTimeoutForStreamingResults参数的,所以我们期望能看到这一条命令正常打印。
我尝试直接连接shardingsphere-proxy去执行这一条命令:
依旧没有日志。并且我们用
show variables查询这个变量的值发现也是没有改变的。看起来这条SET命令压根儿就没执行?不过
show variables的日志是有打印的于是我们打开shardingsphere-proxy自己的sql日志,这个时候我们发现
SET net_write_timeout的日志有输出,并且输出了不止1次。但是和底层mysql通信的日志还是没有打印出来。可以看到,这里逻辑SQL打印了4次,为什么是4次呢?这里也只能通过源代码去找答案。
省去枯燥的代码分析过程,直接给结论:
SET net_write_timeout命令匹配到了BroadcastDatabaseBackendHandler处理器,会依次在所有的逻辑库上执行(对于这实现我有疑惑,为什么不是当前逻辑库,而是所有逻辑库)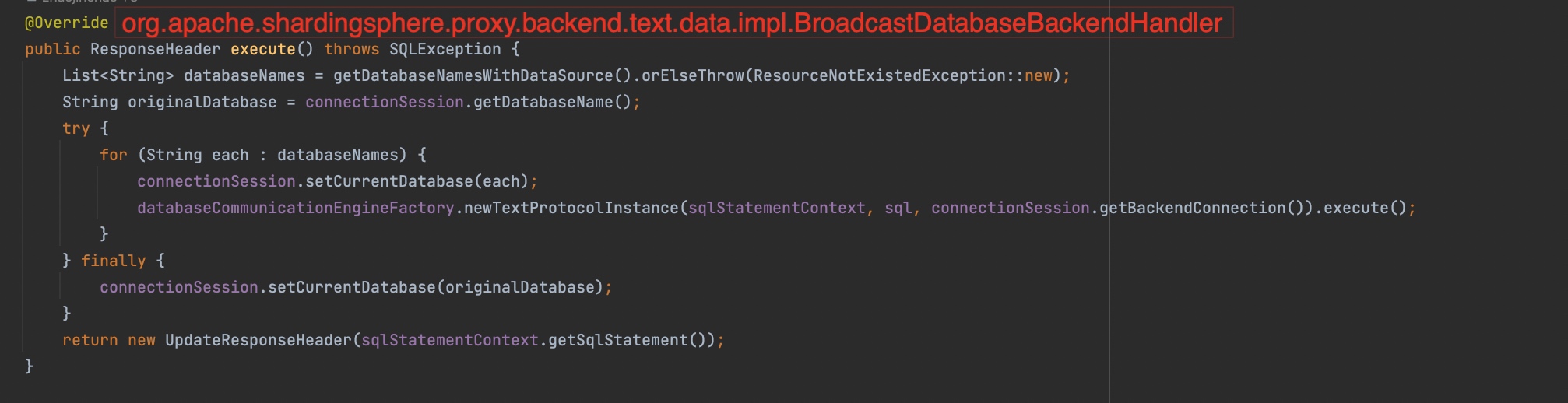
上面的代码展示了
SET net_write_timeout命令的执行流程:会遍历所有的逻辑库来执行对应的语句,而我们刚好有4个逻辑库,这也解释了上面为什么打印出了4条逻辑SQL。但是为什么SQL执行了,一来没有打印出对应的mysql层面的日志,二来set完之后查询查出来的还是旧值(其实这两个是同一个问题)我们顺着这个执行流程往下看,中间省去跟踪代码链路的过程,直接快进到我们找到问题的地方:
org.apache.shardingsphere.proxy.backend.communication.jdbc.connection.JDBCBackendConnectionJDBCBackendConnection管理了proxy和底层物理库之间的连接,它们之间的关系应该是1对多,1个session对应一个JDBCBackendConnection,管理N个和底层物理库之间的连接。并且JDBCBackendConnection内部有一个“连接缓存池”,用于单次查询过程中的复用。但是这个“连接缓存池”的key只用了dataSourceName(物理库标识),而没有使用databaseName(逻辑库标识)。这就导致了如果多个逻辑库下的物理库标识同名,那就存在连接串用的隐患。
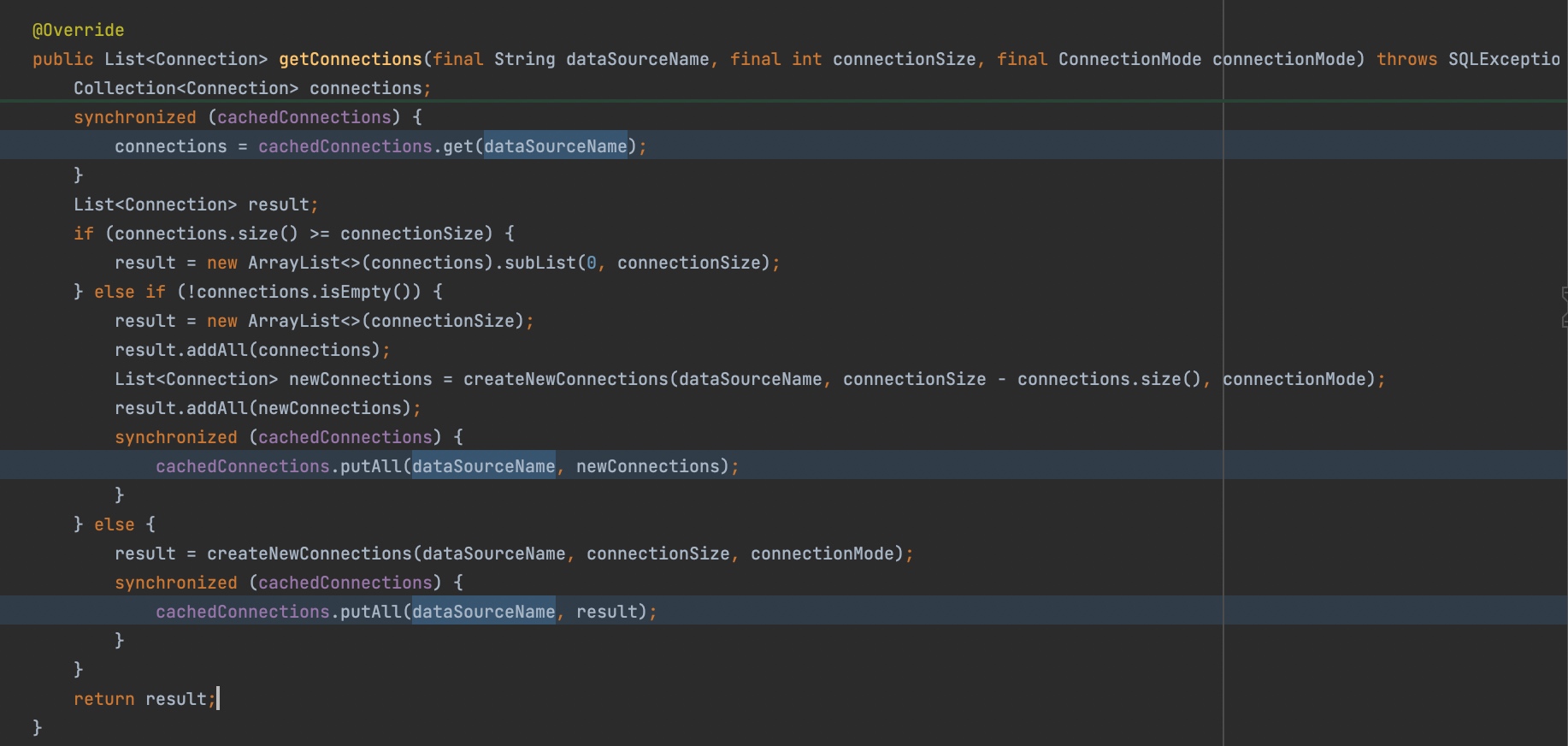
而我们定义的4个逻辑库,它们后面挂的物理库标识都是一样的。比如我们的模块叫
order,我们定义了- 一个主逻辑库
order
- 2个从逻辑库
order_slave_1、order_slave_2
- 一个用来做同步的逻辑库
order_sync(主要是一些参数配置不同于主逻辑库(比如socketTimeout会放大一些)) 而它们对应的物理库都是order_0、order_1...order_15,假设我们定义了16个分库
这个时候当我在shardingsphere-proxy执行一条
SET net_write_timeout=61语句时,会依次在每一个逻辑库上执行。假设当前的逻辑库的顺序是order_slave_1、order_slave_2 、order、order_sync。那么这条语句首先会在order_slave_1上执行,order_slave_1上有16个分库,那么此时广播路由会依次在每一个物理库上执行,那么就会创建16个连接,然后依次执行SET net_write_timeout=61。并且这16条连接会分别以物理库标识order_0、order_1...order_15为缓存key保存在JDBCBackendConnection的“连接缓存池”中。那么在执行到第二个逻辑库
order_slave_2时,由于物理库标识名也是order_0、order_1...order_15。所以此时不会创建新的物理连接,而是直接复用了原来的连接。但是这个时候相当于用的是逻辑库order_slave_1里配置的物理库的连接以及参数。所以这里的缓存key不能只有一个dataSourceName,在多个逻辑库如果有同名的物理库标识的话就会存在连接串用的问题。所以缓存key需要加上databaseName,去官网跟踪了一下,后续的版本也fix了这个问题。
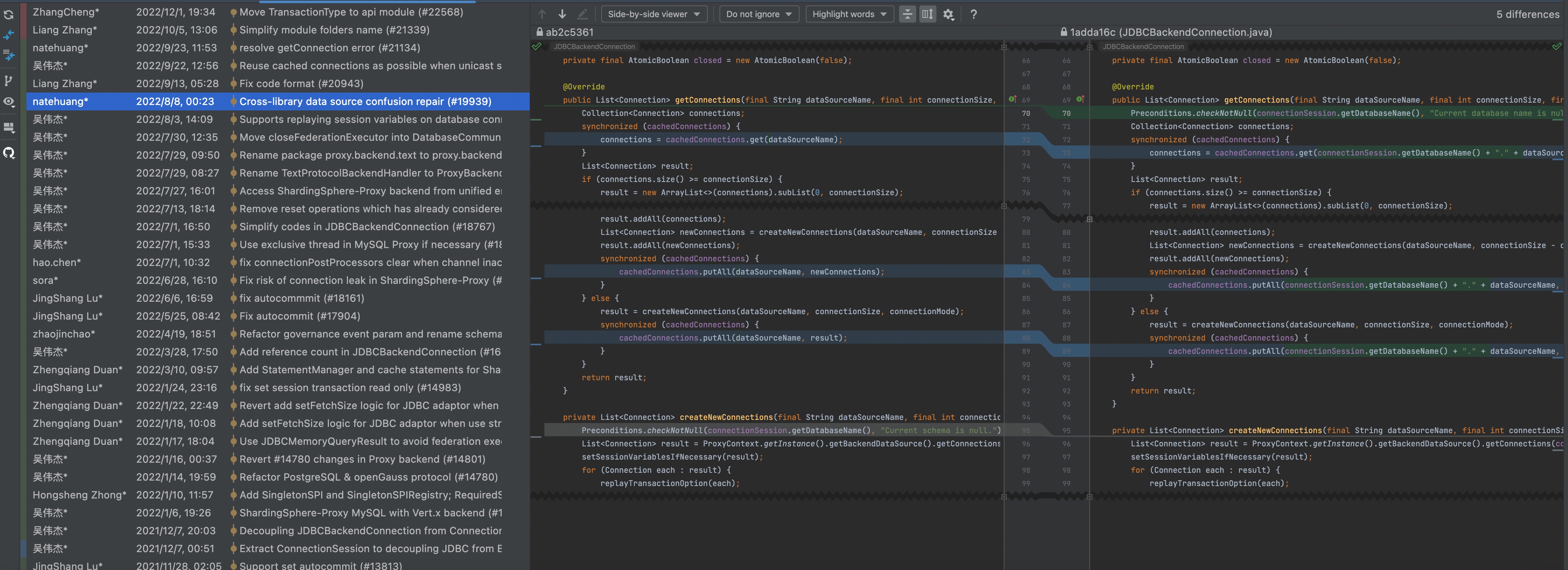
这个"连接缓存池"会在每次执行完语句这后清空掉,所以这种“串用连接”的现象只会影响这种垮多个逻辑库执行的查询。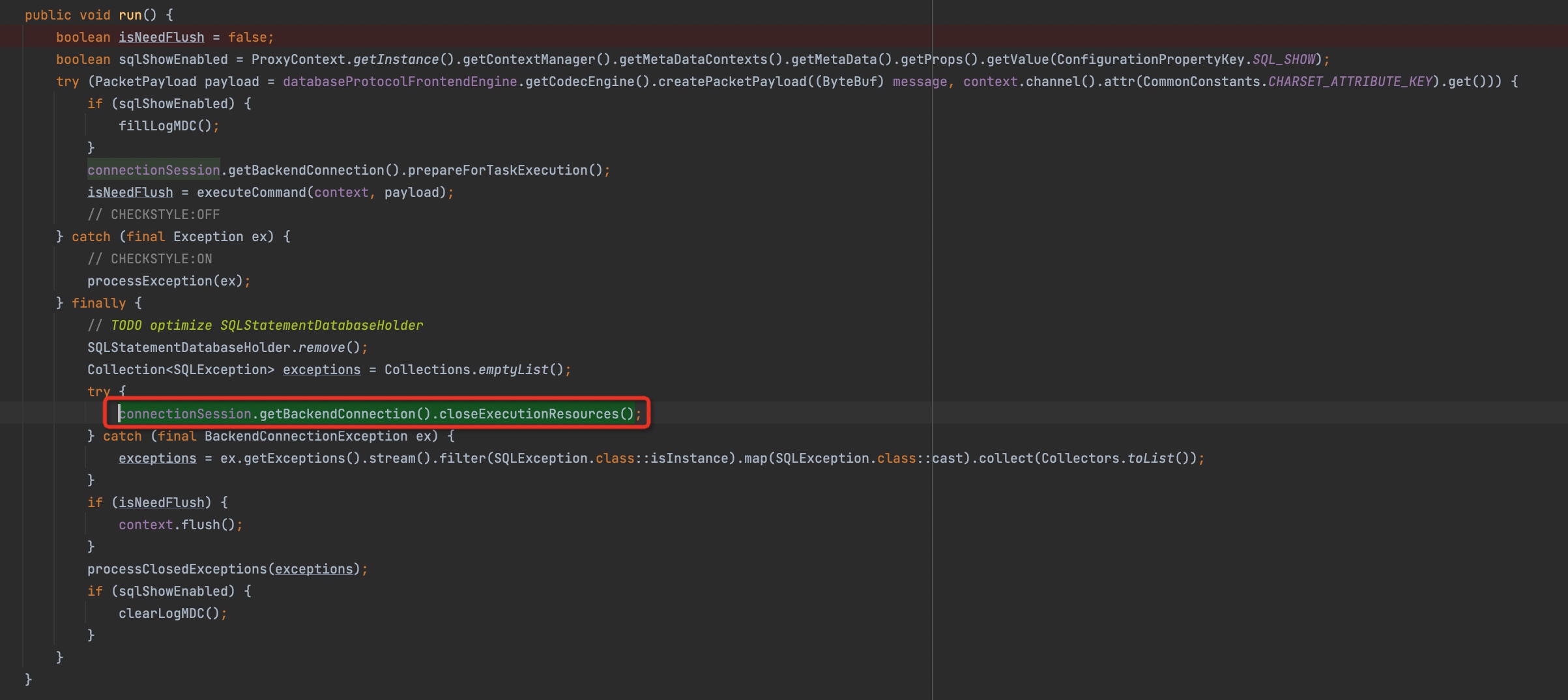
而对于
show variables like 'net_write_timeout'这个语句其实走的是单播路由,也就是在当前的逻辑库下随便找一个物理库执行。但是刚才set的时候走的完全是另外一个逻辑库的连接,所以查出来还是原值。net_write_timeout和异常
那么,为什么
set net_write_timeout没执行,流式查询就会报错呢?我们先简单介绍一下流式查询。它和我们认知里的普通查询有什么区别呢?对于数据库查询,我们可以简单的分解成4个步骤:
- 客户端发送查询语句给数据库
- 数据库查询数据
- 查询完之后数据库把数据发送给客户端
- 客户端读取数据
而对于普通查询和流式查询最主要的区别,就在第三步和第四步。普通查询会把buffer里的数据读完才返回给上层,此时数据全部都被读取到应用的内存里。所以在查询结果集过大的时候,很容易导致内存溢出。而流式查询就是为了解决这一问题,它并不是一次性把buffer的数据读完,而是读一部分,处理一部分,如果是处理速度跟不上生产速度的话,整个tcp的传输窗口会满,那么此时数据库也不能再往buffer里写数据了。等到消费慢慢跟上了,才能继续写数据(这里又涉及比较多的tcp协议相关的知识,比如滑动窗口机制、zero-window等等,有兴趣的可以去看看tcp协议相关的内容)。而mysql无法往buffer里写数据的时间超过net_write_timeout,那么mysql就会把这个连接断开。
所以mysql-connector针对于流式查询会先执行一句
set net_write_timeout,默认是600s,保证这个timeout足够大,降低上述问题出现的概率。而在我们分库分表的场景里,这个问题可能会被放大N倍,因为我们分成了N个库,每个库都会有一个独立的连接去做流式查询,而我们去读取数据又是串行处理的的,所以会导致越靠后的分库的数据越晚被消费,从而导致无法写数据的时间会越长,也就更容易出现等待时间超过net_write_timeout而被mysql断开连接。
两段流式查询?
由于我们是通过流式查询直接查询的shardingsphere-proxy,那么从客户端到shardingsphere-proxy再到底层的mysql物理库之间到底是怎么交互的?是两段都是流式查询吗?shardingsphere-proxy又是如何把流式的信息传递给底层mysql的?
结论我先列一下。shardingsphere-proxy和底层mysql交互具体是用流式查询还是普通查询和client与shardingsphere-proxy之间怎么交互没有关系,而是它自己的执行引擎根据具体的sql情况来决定的。
在shardingsphere-proxy的上下文里,有一个叫做【连接模式】的概念。它是通过连接模式来决定和底层mysql是用流式查询还是普通查询。shardingsphere-proxy主要分成几个核心步骤:
- 解析,解析你的sql,主要是为了获取表名、路由键等关键信息,用于后续的路由匹配
- 路由,根据解析完的结果,找到应该走的路由
- 改写,根据路由信息或者是场景需要改写发往底层mysql的sql,最常见的就是改写表名,增加分库信息
- 执行
- 根据路由和改写结果,生成执行计划,比如全库表路由,会生成整个库表的执行语句列表
- 准备
- 确定对应的【连接模式】,【连接模式】通过配置的
maxConnectionSizePerQuery和本次查询在一个物理库上需要执行的sql语句的数量共同决定。maxConnectionSizePerQuery的含义是,单次查询在单个物理库上的最大连接数。如果maxConnectionSizePerQuery大于本次查询在一个物理库上需要执行的sql语句的数量,那么就可以用流式查询,反之则只能用普通查询。默认的maxConnectionSizePerQuery配置为1,也就是只要单个连接要执行的sql超过1条,那就无法使用流式查询。 - 获取必要的连接
- 根据获取的连接再创建statement,并根据链接模式看要不要setFetchSize(mysql)
- 执行,在对应的statement上执行,得到resultSet,如果是流式查询,那么等到归并的时候才会去具体读取结果。如果不是,那么直接读取所有结果到内存
- 归并,归并查询结果,并做一些如分页等处理
下面截取了几段源代码,也能和上面的结论步骤相互印证
这里的
aggregateSQLUnitGroups()会把执行单元按照底层mysql库维度聚合,然后根据单个库上需要执行的sql数量和maxConnectionSizePerQuery的配置来决定是用哪种【连接模式】
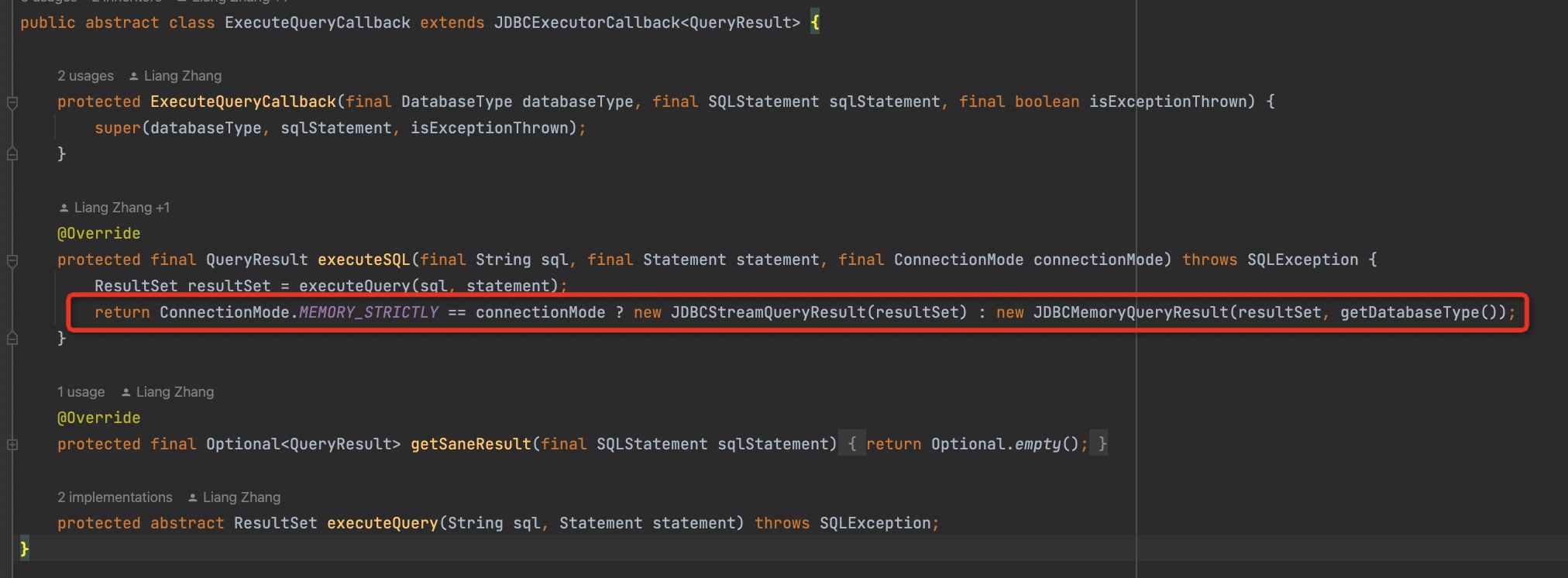
创建statement时会根据【连接模式】来决定要不要开启流式查询

执行完sql,会根据【连接模式】来构造不同的resultSet
另外,上面的例子里是分库不分表的场景。而对于既分库又分表的场景,如果要执行全量etl,由于单个物理库内要执行的sql数量大于1,是不是无法走流式查询?这个答案是否定的,因为shardingsphere-proxy在改写那一步里还有一个聚合SQL的逻辑,也就是它会把多张表的数据用
UNION ALL关键字聚合成一个语句,这样就变成了一条SQL,也就又可以使用流式查询了。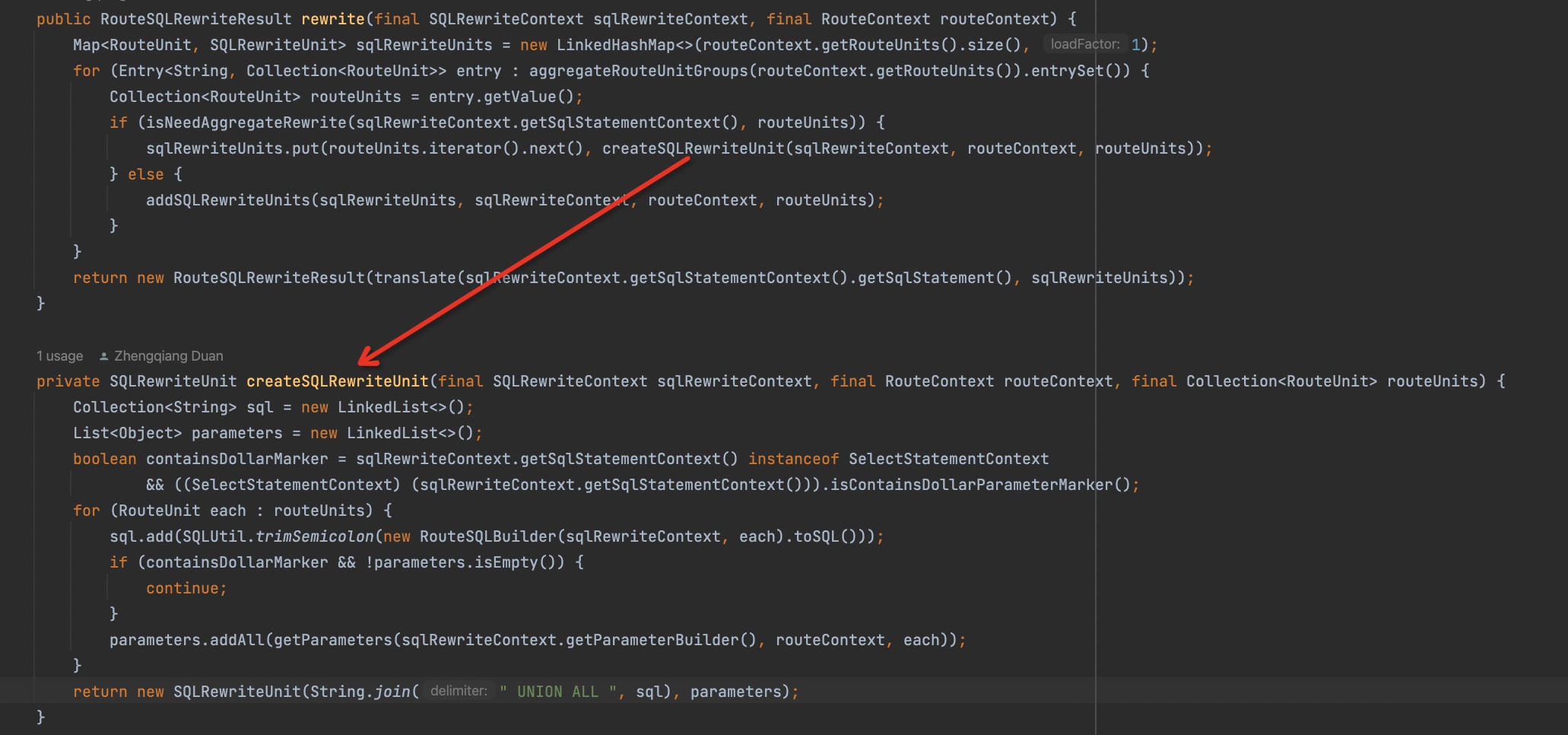

解决
问题已经明确并且我们已经深入了解了其原理。这里提供两种解决思路
- 修复前面提到的shardingsphere-proxy连接串用bug,并且在数据源上配置
netTimeoutForStreamingResults=一个很大的值
- 修改canal源代码,把实时同步反查询的库和etl的库分开。也就是不用shardingsphere-proxy来做etl,而用一个汇总的单库来做。这种方案的前提是你需要有一个实时同步的汇总的单库。
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/shardingsphere-proxy-with-stream-query
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts