type
status
date
slug
summary
tags
category
icon
password
AI summary
背景
继前一篇文章做的一些实验,发现在这条路上有点停不下来了。毕竟纸上得来终觉浅,当你的理论知识在实验中得到证实或者通过实验验证理论中比较模糊的点,都是一件非常爽的事情。
今天的实验主要是大字段的
full update。full update指全量更新,MySQL 8.0开始支持大对象的部分更新(partial update),不过在用户侧能使用的api上还只支持json字段的几个函数(如json_set() 、json_replace() 、json_remove())。这里先介绍个工具——
inno_space,本文我们会使用它来分析ibd文件。最开始是想使用innodb_ruby的,但是它不支持MySQL 8.0。关于inno_space的相关信息可以查看http://mysql.taobao.org/monthly/2021/11/02/和它的github仓库前置知识点
MySQL 8.0对于Uncompressed LOB的结构改造
阅读这篇文章之前你需要掌握一些知识点,以便于你更好的理解。MySQL 8.0为了支持json类型字段的部分更新(partial update),对非压缩的溢出页(Uncompressed LOB)的结构做了改造。改造之前,对于需要多个溢出页保存的字段,它们之间会形成一个单向链表,且每个页面都是一种同类型
FIL_PAGE_TYPE_BLOB。这种结构最大的问题就是无法根据offset快速获取到对应数据,必须一页一页的搜索,这在溢出页数量越大时性能影响也越大。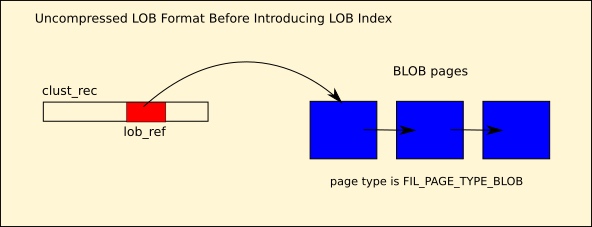
而改造之后,增加了三种新类型:
FIL_PAGE_TYPE_LOB_FIRST(溢出页首页)
FIL_PAGE_TYPE_LOB_INDEX(溢出页索引)
FIL_PAGE_TYPE_LOB_DATA(溢出页数据)。
如下图所示,溢出页之间不再有指针,而是由
Index Entry来统一管理。FIL_PAGE_TYPE_LOB_FIRST页上预留了10个Index Entry 的位置。超过10个溢出页那就需要分配额外的FIL_PAGE_TYPE_LOB_INDEX页来存放。FIL_PAGE_TYPE_LOB_FIRST上除了有Index Entry之外,还保存有实际溢出列的数据,所以第一个Index Entry一般是指向本页面的数据offset。可以看到,FIL_PAGE_TYPE_LOB_FIRST的命名单纯是从它所处的位置出发,并非功能,因为它很“综合”,既有索引又有数据。
通过这样的结构改造,那么给定一个偏移量,就很容易定位到具体的溢出页,提升了性能。改造之后,首页的数据容量为15680,而数据页的容量为16327。
关于上面的知识点,你感兴趣的话,可以在官网找到更详细的描述,里面还有官方做的性能测试
全量更新的流程
溢出页字段的全量更新(full update)的流程分成两种情况:
- 如果更新后无需溢出存储,那么会直接更新到聚簇索引中inline保存
- 如果更新后仍需溢出存储,那么会根据溢出量分配新的溢出页来承载
第二种情况的流程如下图所示:
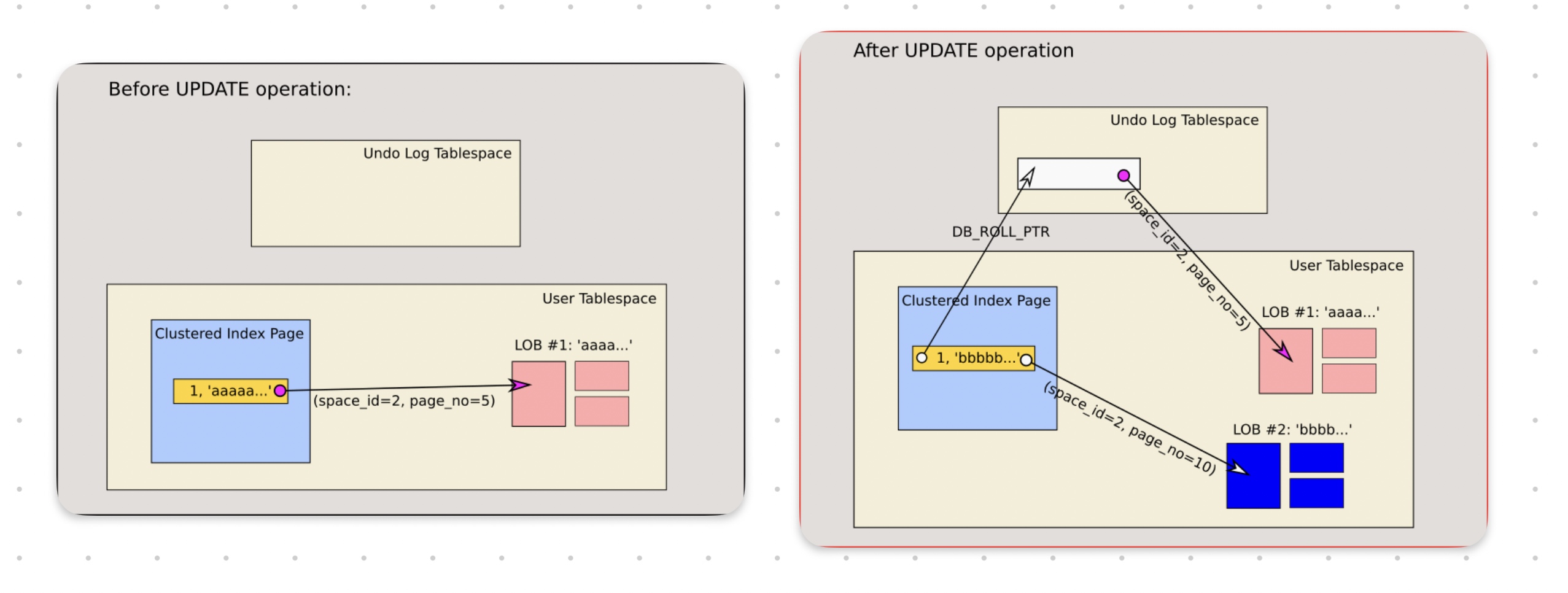
大致步骤为:
- 创建更新后需要的溢出页
- 写入数据
- 更新聚簇索引里的溢出页指针指向新溢出页的首页
- 写入undo log并更新回滚指针
实验
了解完上面的知识点,下面开始正式实验,我们先创建一张包含大字段的测试表并构造一条占据一个溢出页的测试数据
更新1次
然后我们来对它做一次更新,让它占据两个溢出页
我们通过inno_space观察一下更新前后的ibd文件

更新前只有1个溢出页(1个首页),更新后变成了3个溢出页(2个首页 + 1个数据页)。不过此时Page5已经失效了(
BLOB FLAGS = 1)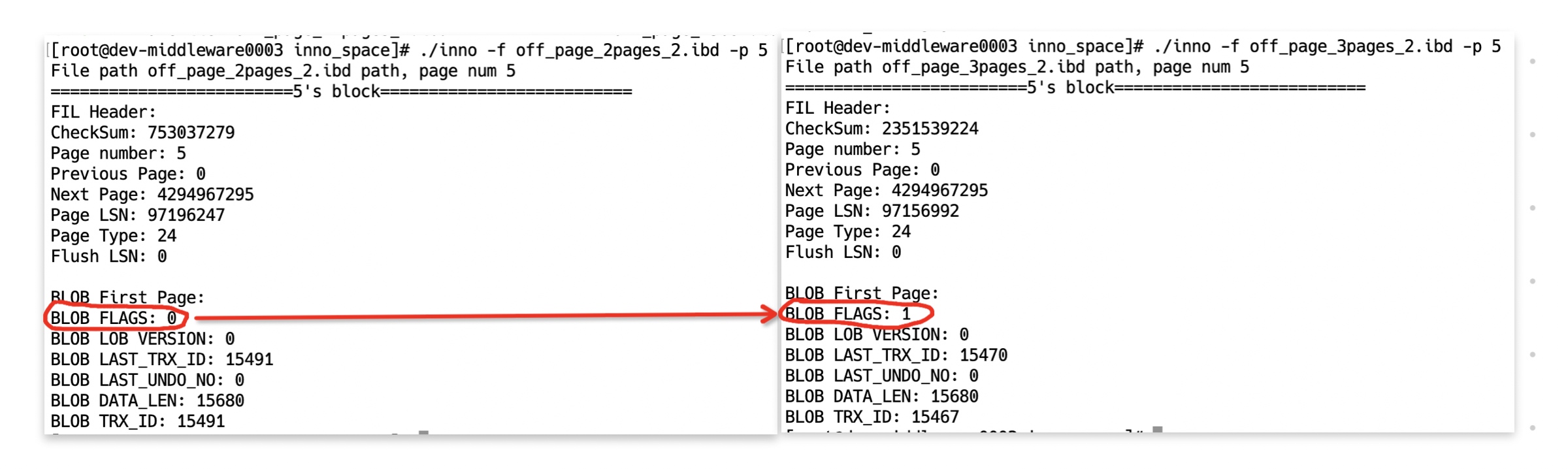
Page6是从Page5复制出来的,而Page7则是新创建的用于保存此次更新的数据页。可以看到Page6里的
BLOB FLAGS = 0结合前面知识点里关于full update的示意图,这一块应该比较容易理解。
更新9次
我们继续更新,期望每执行一次都增加一个溢出页,前9次执行都符合预期。我们来看看第9次执行完成时的页类型分布。
总共有19个溢出页,下面我们用表格来分析一下这19个溢出页是怎么形成的,关键点有2个:
- 每次更新都要从原溢出页复制出新页,有失效的页可以优先复用,所以可以看到交替更新每一次都可以复用前一次失效的页
- 看起来同类型的页有优先复用的策略?(这个只是我的猜想,待考证)
行为 | 溢出页使用情况 |
插入 | 5 |
第1次更新 | 6、7 |
第2次更新 | 5、8、9 |
第3次更新 | 6、7、10、11 |
第4次更新 | 5、8、9、12、13 |
第5次更新 | 6、7、10、11、14、15 |
第6次更新 | 5、8、9、12、13、16、17 |
第7次更新 | 6、7、10、11、14、15、18、19 |
第8次更新 | 5、8、9、12、13、16、17、20、21 |
第9次更新 | 6、7、10、11、14、15、18、19、22、23 |
最终还留下来了5、8、9、12、13、16、17、20、21这9个失效页。这些就是所谓的碎片,但是在
information_schemas.tables表的data_free字段并看不出来。实际表(ibd)文件大小是400k,总共25页,其中9个是失效页。我们通过
重新整理表后,文件缩小到272k,减少了8页,比预期少了1页,我们再用
inno_space来分析一下我们发现溢出页的减少其实是符合预期的(19 -> 10减少了9页),但是INDEX PAGE的数量竟然从1变成了2,导致整体页面只减少了8个。
optimize table之后,为什么会增加一页INDEX PAGE呢?按理说索引页的数量应该和记录数相关,表里始终就只有一条记录,我百思不得其解。Google了一圈也没找到相关资料。并且试了一下,插入数据是可以复用第5页的,那么第5页的这个INDEX PAGE应该是失效页,但是从INDEX PAGE的结构里好像也没找到有标志状态的字段。问了一下Notion AI,说可能是在
optimize table时会预留一些空间以备后续的数据插入和索引构建。当然不能完全确信~更新10次
我们继续更新,这一次的结果和之前不同,一下子增加了2个页。
这里查出来的data_length字段只包含生效的页面的大小,被标记为失效的页面并不统计在里面,这里最后减1减的是数据索引页(Index Page),所以这里的第三列统计的是除聚簇索引外的生效页的数量
我们继续用
inno_space来分析一下页的类型,看看这次多出来的1个页是什么?原来是多了1个溢出页索引页(
FIL_PAGE_TYPE_LOB_INDEX),因为溢出页首页里只预留了10个索引位,超过10个之后就需要分配额外的索引页来存放。这也印证了我们前面说的知识点。更新15次
我们继续更新,发现更新15次之后,又出现了一个诡异的现象。这一次除聚簇索引外的生效页面数量直接从16增长到了80。
我们先来看看更新后的页面分布:
再用我们之前的表格分析一下:
行为 | 溢出页使用情况 | 溢出索引页使用情况 |
插入 | 5 | ㅤ |
第1次更新 | 6、7 | ㅤ |
第2次更新 | 5、8、9 | ㅤ |
第3次更新 | 6、7、10、11 | ㅤ |
第4次更新 | 5、8、9、12、13 | ㅤ |
第5次更新 | 6、7、10、11、14、15 | ㅤ |
第6次更新 | 5、8、9、12、13、16、17 | ㅤ |
第7次更新 | 6、7、10、11、14、15、18、19 | ㅤ |
第8次更新 | 5、8、9、12、13、16、17、20、21 | ㅤ |
第9次更新 | 6、7、10、11、14、15、18、19、22、23 | ㅤ |
第10次更新 | 5、8、9、12、13、16、17、20、21、24、25 | 26 |
第11次更新 | 6、7、10、11、14、15、18、19、22、23、26、27 | 28 |
第12次更新 | 5、8、9、12、13、16、17、20、21、24、25、28、29 | 26 |
第13次更新 | 6、7、10、11、14、15、18、19、22、23、26、27、30、31 | 28 |
第14次更新 | 5、8、9、12、13、16、17、20、21、24、25、28、29、32、33 | 26 |
第15次更新 | 6、7、10、11、14、15、18、19、22、23、26、27、30、31、34、35 | 28 |
通过上面2份信息我们可以得出:
- 溢出索引页也会失效,也可以复用,所以更新过程中始终有2个页面在交替复用
- 第15次更新后的溢出数据页的数量是31个,包含
- 16个生效的溢出数据页
- 15个失效的溢出数据页
我们再来看看更新之前的页面分布:
可以看到更新之前是37个页面,其中数据占据了32个页面,还有一个是
FRESHLY ALLOCATED PAGE。而InnoDB分配页面的机制是刚开始是从碎片区开始分配,分配32个页面之后,开始以区(Extent)为单位,一次性分配连续的64个页面,可以利用顺序IO提升性能。看起来应该是这个机制起到了作用。但是我测试下来,这个值是33个页面,而并非32个页面。不知道问题出在哪里。
更新后不溢出
更新之后查看ibd文件,发现name字段值已经inline存储了
并且此时溢出页的flag也标记为失效了
溢出页首页的结构
这里我们顺势来分析一下溢出页首页的结构,整体结构如下图所示:

字段 | 字节数 | 描述 |
OFFSET_VERSION | 1 | 表示lob的版本号,当前为0,用于以后lob格式改变做版本区分 |
OFFSET_FLAGS | 1 | 目前只使用第一个bit,被设置时表示无法做partial update, 用于通知purge线程某个更新操作产生的老版本LOB可以被完全释放掉 |
OFFSET_LOB_VERSION | 4 | 每个lob page都有个版本号,初始为1,每次更新后递增 |
OFFSET_LAST_TRX_ID | 6 | ㅤ |
OFFSET_LAST_UNDO_NO | 4 | ㅤ |
OFFSET_DATA_LEN | 4 | 存储在该page上的数据长度 |
OFFSET_TRX_ID | 6 | 创建存储在该page上的事务id |
OFFSET_INDEX_LIST | 16 | 维护lob page链表 |
OFFSET_INDEX_FREE_NODES | 16 | 维护空闲节点 |
LOB_PAGE_DATA | 600 | 存储数据的起始位置,注意第一个page同时包含了lob index 和lob data,但在第一个lob page中只包含了10个lob index记录,每个lob index大小为60字节 |
Index List 和 Index Free Nodes
我们先看
Index List和Index Free Nodes这两个区域的数据:更新9次,刚好10个溢出页时
更新10次,11个溢出页时
看起来在创建
Index Entry时,会根据Index Free Nodes里有没有剩余空间来决定是要新分配页还是在已有页上创建。创建完之后再维护到Index List里。Index Entry
我们再来看看
Index Entry,每个Index Entry占据60个字节,具体结构如下偏移量 | 字节数 | 描述 |
OFFSET_PREV | 6 | Pointer to the previous index
entry |
OFFSET_NEXT | 6 | Pointer to the next index entry |
OFFSET_VERSIONS | 16 | Pointer to the list of old
versions for this index entry |
OFFSET_TRXID | 6 | The creator transaction
identifier. |
OFFSET_TRXID_MODIFIER | 6 | The modifier transaction
identifier |
OFFSET_TRX_UNDO_NO | 4 | the undo number of creator
transaction. |
OFFSET_TRX_UNDO_NO_MODIFIER | 4 | The undo number of modifier
transaction. |
OFFSET_PAGE_NO | 4 | The page number of LOB data
page |
OFFSET_DATA_LEN | 4 | The amount of LOB data it
contains in bytes. |
OFFSET_LOB_VERSION | 4 | The LOB version number to which this index
entry belongs. |
它在实际保存数据之前的600个字节。我们只分析最后两个
Index Entry,可以看到对应的OFFSET_PAGE_NO是0x17=23 和0x16=22,跟我们前面表格里分析的生效页一致。参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/mysql-uncompressed-page-full-update
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!