type
status
date
slug
summary
tags
category
icon
password
AI summary
PreparedStatement是什么
PreparedStatement是java.sql包下面的一个接口,看看JavaDoc对于它是如何描述的:
大致意思就是:PreparedStatement代表一个”预编译好的”SQL Statement。这个Statement可以被多次执行,用以提升效率
一般地,我们通过Java来执行SQL时不可避免的会用到Statement或者PreparedStatement:
PreparedStatement和Statement对比
PreparedStatement有点类似模板的概念,把一条SQL的静态部分和动态部分拆分了开来,这样带来的好处:
- 支持参数动态化
- 提高了可读性
两个误区
PreparedStatement能提升性能
根据JavaDoc的描述,PreparedStatement貌似是可以提升性能的。但是PreparedStatement只是个接口,底层的实现逻辑都在具体的数据库驱动中。是不是真的能提升性能还得看
connection.prepareStatement()方法怎么实现呢PreparedStatement能有效防止SQL注入
和上面的误区存在同样的问题,这两个误区产生的原因都是没有基于一定的前提来看待PreparedStatement,下面我们以MySQL的官方驱动为例来看看这两个结论是不是都是对的
MySQL下的PreparedStatement
PreparedStatement在MySQL驱动中的实现分为client模式和server模式。主要是通过数据源url上的
useServerPrepStmts参数指定的。默认为false,使用client模式。client模式下的PreparedStatement
在client模式下,
prepareStatement方法并不会与MySQL服务端交互,会在本地把SQL解析为ParseInfo,解析过程这里就不展开了,ParseInfo 里最核心的成员变量是一个二维的字节数组byte[][] staticSql 。staticSql[][]里保存的就是解析后的sql信息,第一维就是按照?的位置做分割,第二维则是表示对应的字符。为什么第二维不直接用String来表示,而是用byte[]?
主要是空间上的考虑。一个String最少占用的空间是很大的,1个字符的String在64 bit的JVM开启压缩指针的前提下会占用32Byte的空间,未开启状态会到40Byte。JDK 1.6以前的版本会在这个基础上分别再加8Byte存放offset、count值,改为byte[]数组后会小一些,单个字符的byte[]在64bit下可以降低到24字节(其实也挺大的,数组除了对象头部还有一个位置保存数组的长度,加上1个字符的1~4字节按照8字节对齐到24字节)
而在
execute 时,则通过staticSql[][]配合上对应的参数,替换成最终的SQL,最后把替换之后的SQL发送给MySQL服务端。我们测试一下在client模式下,上述两个结论是否成立,测试代码如下:
- 理论上性能提升是不存在的,或者说没有明显性能提升的点。相比Statement,PreparedStatement还多了一步本地的参数解析替换(不成立)
后面我们会通过实验来测试,测试代码详见附录
- SQL注入这个通过1个测试用例,简单抓包,发现在驱动这一层做了转义(成立)
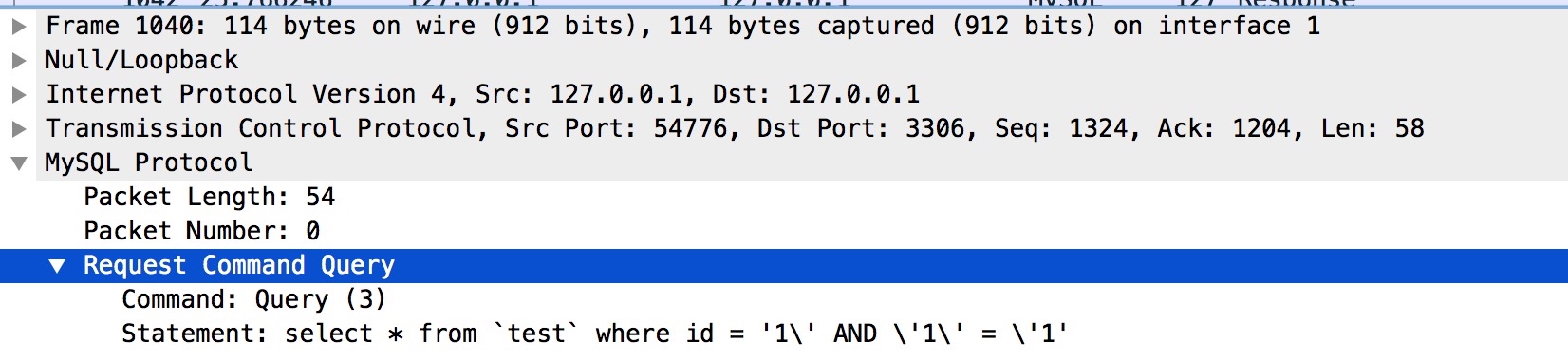
相关源码如下,是在设置参数(setXxx)的时候做的转义:
server模式下的PreparedStatement
我们通过下面的测试代码来感受一下:
运行上面的测试程序,抓包来看看:
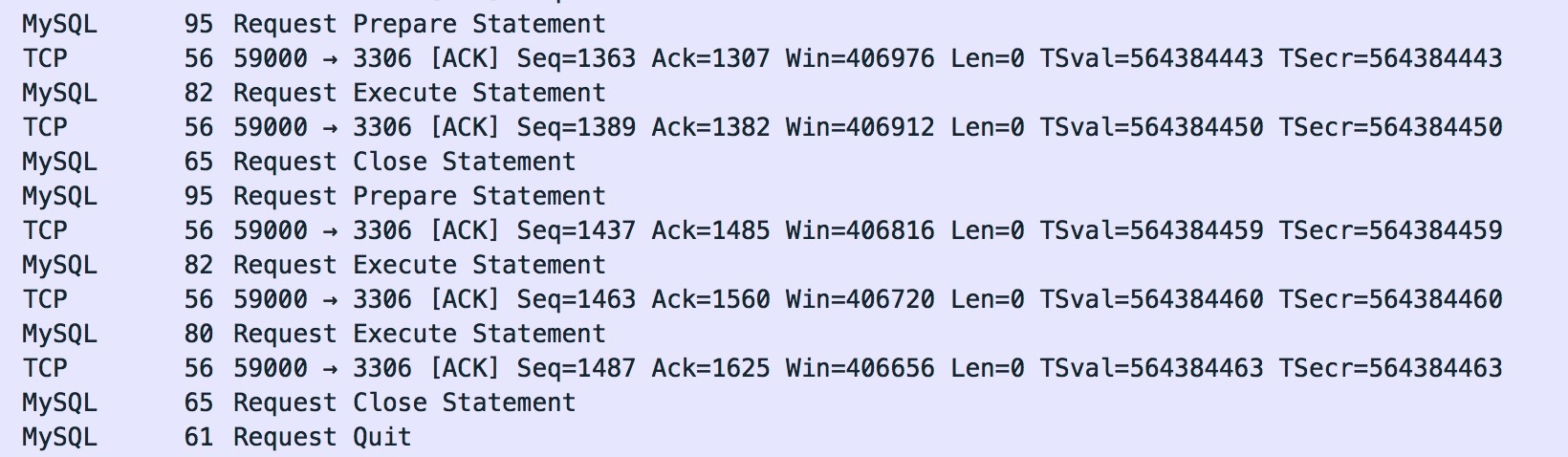
server模式下的
PrepareStatement ,调用它的prepareStatement方法都会和MySQL服务端交互。整个查询过程从原来的Query Statement变成了Prepare Statement + Execute Statement + Close Statement。我们再看看具体的包数据:Prepare Statement
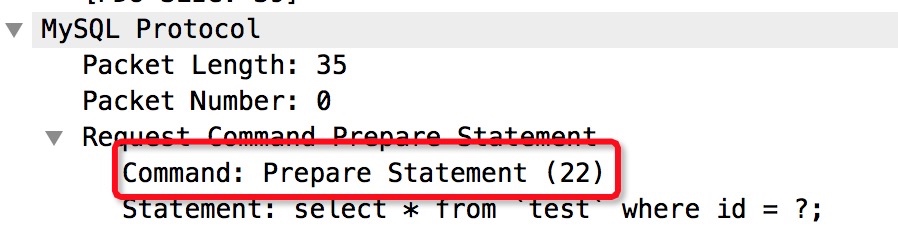
请求包:
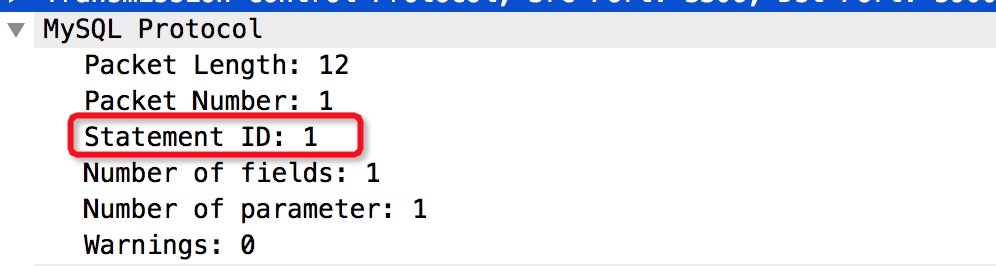
响应包:
Prepare主要是发送一条带
?的SQL给MySQL服务端,MySQL执行预编译(或者叫硬解析)动作,硬解析得到语法树(stmt->Lex),缓存在线程所在的prepareStatement cache中。此cache是一个HashMap,Key为StatementId,最后返回这个StatementId,指代这条预编译结果。这里介绍一下,MySQL执行一条SQL的过程包括以下阶段 词法分析->语法分析->语义分析->执行计划优化->执行。词法分析->语法分析这两个阶段我们称之为硬解析。词法分析识别sql中每个词,语法分析解析SQL语句是否符合sql语法,并得到一棵语法树(Lex)。对于只是参数不同,其他均相同的sql,它们执行时间不同但硬解析的时间是基本相同的。
Execute Statement
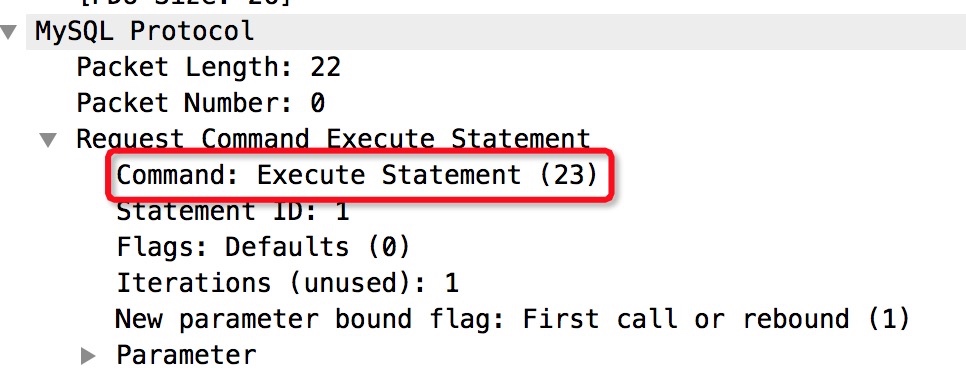
Execute主要是客户端发送StatementId和参数等信息。注意这里不需要再发sql过去。服务器会根据StatementId在prepareStatement cache中查找得到硬解析后的stmt,并设置参数,就可以继续后面的优化和执行了。
Close Statement
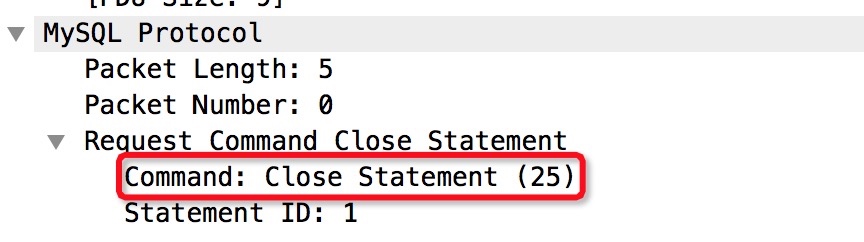
PreparedStatement.close()操作也会触发与MySQL服务端交互,关闭刚才硬解析好的那条PreparedStatementMySQL General Log
再来结合MySQL服务端的日志看一下:
这里可以看出来,与client模式相比:对于一个简单的SQL执行,需要与数据库多两次交互。整体上对于性能来说,在大多数简单查询的场景下,肯定是弊大于利的。
除非是Prepare之后,对同一个PreparedStatement执行很多次Execute,才有可能提升性能。存在这种可能性吗?试着打开参数
cachePrepStmts=true,再试试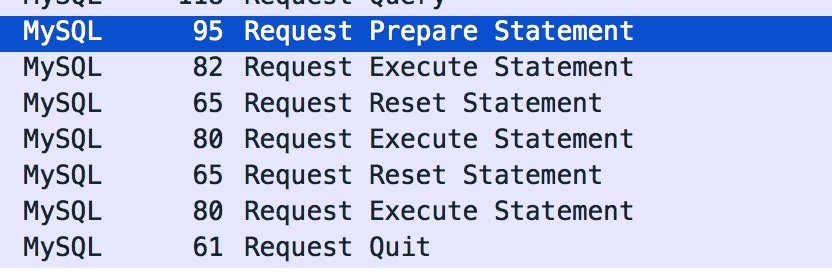
是不是惊喜的发现,只有一次Prepare Statement了?没有Close Statement了?但是怎么多了一种Reset Statement,这个是干嘛的?
MySQL Bug
我们注意到官网上有这么一段话:

看官网这个描述,这种情况不是只会出现在有大字段存在的场景吗,我这个测试表就一个ID字段,怎么会出现这种情况?
只能从源码里再去找找答案了(下面是8.0.16的connector源码):
clearParameters这一步是在ServerPreparedStatement.close()阶段被触发的,还有个前提是打开了PreparedStatement缓存。很容易理解,因为PreparedStatement需要重用,所以每次用完需要把之前的参数信息都清空掉。上面的代码显示了在清空参数的过程中,会判定有没有大字段(blob, clob),如果有的话hadLongData变量会被赋值成true。上面的代码我们分成步骤A和步骤B来看,对于步骤B来说,逻辑上是存在大字段且需要
clearServerParameters时,才发送Reset Statement,这个毫无疑问是false。但是对于步骤A来说,由于不存在大字段,所以会将LongParameterSwitchDetected这个参数的值设置成true。这个时候会触发另外一个逻辑:这个逻辑是在
ServerPrepareStatement.prepare()时触发的,只要LongParameterSwitchDetected这个参数为true,那么就是触发调用Reset命令。我感觉这个参数是用来解决官网说到的最后一点问题的:一个字段从大字段变成了正常字段的场景。然而驱动里的逻辑是:只要没有大字段,就会Reset,缺少了从有->没有的这个过程转变信息。感觉是驱动的BUG于是翻看了下
5.1.47版本的驱动代码,发现老的逻辑是没有问题的,且正如我所猜想的: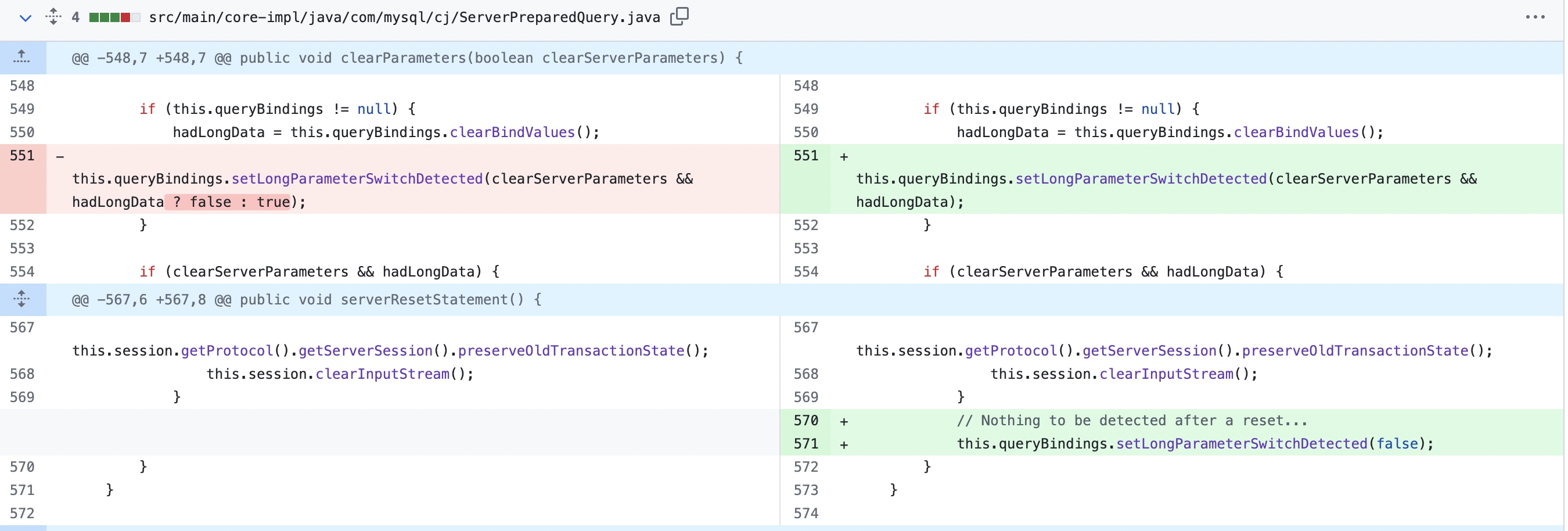
和PreparedStatement相关的参数
- useServerPrepStmts
- cachePrepStmts
- prepStmtCacheSize
- prepStmtCacheSqlLimit
useServerPrepStmts前面我们讲过,用来控制是使用ClientPreparedStatement还是ServerPreparedStatement。默认false
cachePrepStmts用来控制是否缓存对应的PreparedStatement,无论是ClientPreparedStatement还是ServerPreparedStatement。默认false
prepStmtCacheSize用来限制缓存的PreparedStatement的数量,connection维度。默认25
prepStmtCacheSqlLimit用来限制可缓存的PreparedStatement的原始sql的长度。默认256
附录
性能测试代码
为了测试ClientPreparedStatement的性能,最好可以避免网络的干扰。下面我们直接不发送具体的请求,在本地测试:
测试结果
100w次循环(cachePrepStmts=false)测试结果:
testPreparedStatement cost:6829 ms
testStatement cost:2047 ms
100w次循环(cachePrepStmts=true)测试结果:
testPreparedStatement cost:4375 ms
testStatement cost:2104 ms
测试结论
这里可以看出ClientPreparedStatement相对Statement性能反而更差,开启cachePrepStmts能提升一定的性能,当然这里本来就是空间换时间,并且这里的场景单一,只有一个SQL,命中率100%,并不具备参考性。也可以看出其实简单sql的解析成本也很低。
结论
个人不建议开启
useServerPrepStmts和cachePrepStmts。因为:- cache是connection维度的,同一条SQL在不同的connection中会被放大N倍,如果考虑分库分表的场景,那问题会更加严重。
- 实际使用过程中,我们可能碰到不少in语句,而对于in语句来说,in子句里的元素数量不同,那么SQL也是不同的,同一个场景就有可能产生上百种SQL。此时要么花大量内存来存储,要么就是牺牲命中率。
- 开启cache可能会造成内存占用较多,容易引发系统不稳定,对于MySQL Server也是。
- 从我们自己的实践来看,客户端和服务端去解析SQL的成本都还好,并且我们不允许使用复杂SQL,SQL的复杂度对于解析时间应该也有一定的影响。
参考
- Author:黑微狗
- URL:https://blog.hwgzhu.com/article/mysql-prepared-statement
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!